语言模型的定义和BERT解读
什么是语言模型, 其实用一个公式就可以表示$P(c_{1},\ldots ,c_{m})$, 假设我们有一句话, $c_{1}$到$c_{m}$是这句话里的$m$个字, 而语言模型就是求的是这句话出现的概率是多少.
比如说在一个语音识别的场景, 机器听到一句话是”wo wang dai san le(我忘带伞了)”, 然后机器解析出两个句子, 一个是”我网袋散了”, 另一个是”我忘带伞了”, 也就是前者的概率大于后者. 然后语言模型就可以判断$P(“我忘带伞了”) > P(“我网袋散了”)$, 从而得出这句语音的正确解析结果是”我忘带伞了”.
BERT的全称是: Bidirectional Encoder Representations from Transformers, 如果翻译过来也就是双向transformer编码表达, 我们在上节课解读了transformer的编码器, 编码器输出的隐藏层就是自然语言序列的数学表达, 那么双向是什么意思呢? 我们来看一下下面这张图.
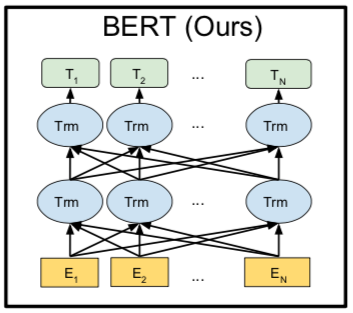
上图中$E_i$是指的单个字或词, $T_i$指的是最终计算得出的隐藏层, 还记得我们在Transformer(一)中讲到的注意力矩阵和注意力加权, 经过这样的操作之后, 序列里面的每一个字, 都含有这个字前面的信息和后面的信息, 这就是双向的理解, 在这里, 一句话中每一个字, 经过注意力机制和加权之后, 当前这个字等于用这句话中其他所有字重新表达了一遍, 每个字含有了这句话中所有成分的信息.
在BERT中, 主要是以两种预训练的方式来建立语言模型:
BERT语言模型任务一: MASKED LM
在BERT中, Masked LM(Masked language Model)构建了语言模型, 这也是BERT的预训练中任务之一, 简单来说, 就是随机遮盖或替换一句话里面任意字或词, 然后让模型通过上下文的理解预测那一个被遮盖或替换的部分, 之后做$Loss$的时候只计算被遮盖部分的$Loss$, 其实是一个很容易理解的任务, 实际操作方式如下:
- 随机把一句话中$15\%$的$token$替换成以下内容:
1) 这些$token$有$80\%$的几率被替换成$[mask]$;
2) 有$10 \%$的几率被替换成任意一个其他的$token$;
3) 有$10 \%$的几率原封不动. - 之后让模型预测和还原被遮盖掉或替换掉的部分, 模型最终输出的隐藏层的计算结果的维度是:
$X_{hidden}: [batch_size, \ seq_len, \ embedding_dim]$
我们初始化一个映射层的权重$W_{vocab}$:
$W_{vocab}: [embedding_dim, \ vocab_size]$
我们用$W_{vocab}$完成隐藏维度到字向量数量的映射, 只要求$X_{hidden}$和$W_{vocab}$的矩阵乘(点积):
$X_{hidden}W_{vocab}: [batch_size, \ seq_len, \ vocab_size]$
之后把上面的计算结果在$vocab_size$(最后一个)维度做$softmax$归一化, 是每个字对应的$vocab_size$的和为$1$, 我们就可以通过$vocab_size$里概率最大的字来得到模型的预测结果, 就可以和我们准备好的$Label$做损失($Loss$)并反传梯度了.
注意做损失的时候, 只计算在第1步里当句中随机遮盖或替换的部分, 其余部分不做损失, 对于其他部分, 模型输出什么东西, 我们不在意.
BERT语言模型任务二: Next Sentence Prediction
- 首先我们拿到属于上下文的一对句子, 也就是两个句子, 之后我们要在这两段连续的句子里面加一些特殊$token$:
$[cls]$上一句话,$[sep]$下一句话.$[sep]$
也就是在句子开头加一个$[cls]$, 在两句话之中和句末加$[sep]$, 具体地就像下图一样:
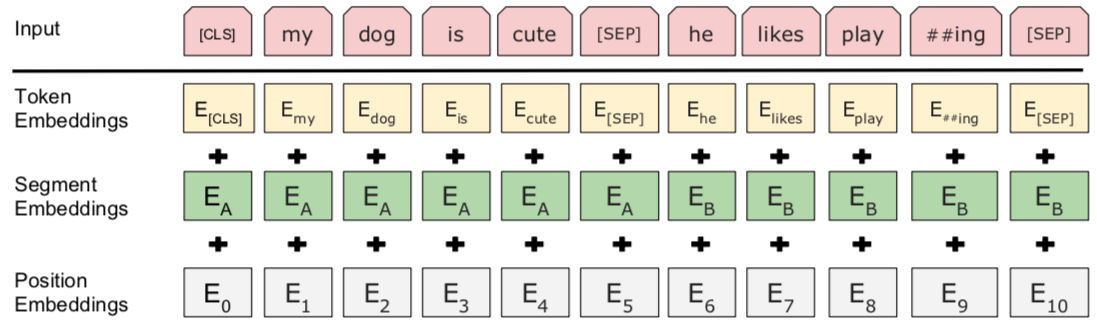
- 我们看到上图中两句话是$[cls]$ my dog is cute $[sep]$ he likes playing $[sep]$, $[cls]$我的狗很可爱$[sep]$他喜欢玩耍$[sep]$, 除此之外, 我们还要准备同样格式的两句话, 但他们不属于上下文关系的情况;
$[cls]$我的狗很可爱$[sep]$企鹅不擅长飞行$[sep]$, 可见这属于上下句不属于上下文关系的情况;
在实际的训练中, 我们让上面两种情况出现的比例为$1:1$, 也就是一半的时间输出的文本属于上下文关系, 一半时间不是. - 我们进行完上述步骤之后, 还要随机初始化一个可训练的$segment \ embeddings$, 见上图中, 作用就是用$embeddings$的信息让模型分开上下句, 我们一把给上句全$0$的$token$, 下句啊全$1$的$token$, 让模型得以判断上下句的起止位置, 例如:
$[cls]$我的狗很可爱$[sep]$企鹅不擅长飞行$[sep]$
$0 \quad \ 0 \ \ 0 \ \ 0 \ \ 0 \ \ 0 \ \ 0 \ \ 0 \ \ \ 1 \ \ 1 \ \ 1 \ \ 1 \ \ 1 \ \ 1 \ \ 1 \ \ 1$
上面$0$和$1$就是$segment \ embeddings$. - 还记得我们上节课说过的, 注意力机制就是, 让每句话中的每一个字对应的那一条向量里, 都融入这句话所有字的信息, 那么我们在最终隐藏层的计算结果里, 只要取出$[cls]token$所对应的一条向量, 里面就含有整个句子的信息, 因为我们期望这个句子里面所有信息都会往$[cls]token$所对应的一条向量里汇总:
模型最终输出的隐藏层的计算结果的维度是:
我们$X_{hidden}: [batch_size, \ seq_len, \ embedding_dim]$
我们要取出$[cls]token$所对应的一条向量, $[cls]$对应着$\ seq_len$维度的第$0$条:
$cls_vector = X_{hidden}[:, \ 0, \ :]$
$cls_vector \in \mathbb{R}^{batch_size, \ embedding_dim}$
之后我们再初始化一个权重, 完成从$embedding_dim$维度到$1$的映射, 也就是逻辑回归, 之后用$sigmoid$函数激活, 就得到了而分类问题的推断.
我们用$\hat{y}$来表示模型的输出的推断, 他的值介于$(0, \ 1)$之间:
$\hat{y} = sigmoid(Linear(cls_vector)) \quad \hat{y} \in (0, \ 1)$