学习链接
https://blog.csdn.net/qq_39388410/article/details/105877505
https://cloud.tencent.com/developer/article/1598413
问题 & 任务
图片场景图生成任务(Image scene graph generation)目标是让计算机自动生成一种语义化的图结构(称为 scene graph,场景图),作为图像的表示。图像中的目标对应 graph node,目标间的关系对应 graph edge(目标的各种属性,如颜色,有时会在图中表示)。
这种结构化表示方法相对于向量表示更加直观,可以看做是小型知识图谱,因此可以广泛应用于知识管理、推理、检索、推荐等。此外,该表示方法是模态无关的,自然语言、视频、语音等数据同样可以表示成类似结构,因此对于融合多模态信息很有潜力。
Scene graph 刚开始提出时[1],被应用到图片检索任务,利用 scene graph 去图片库搜索内容相近的图片。当时使用到的 scene graph 是基于目标检测数据集人工标注的,耗时耗力。随着 Visual Genome 大型数据集的公开,其对超过十万的图片进行了 scene graph 的人工标注,如何自动生成 scene graph 成为了热门的研究任务。
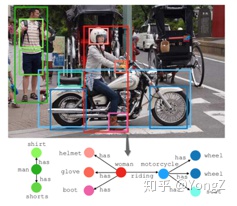
形式化地,记关系集合为R,目标集为O, 目标位置为B (一般是 Bounding box),图像为 I,则图片场景图为G={ B, O, R}。根据给定条件多少,场景图生成任务可以由简单到复杂细分为以下几种:
关系分类(Predicate classification): 给定图中目标位置及类别,对关系进行归类,记为 P(R | O, B, I)。
场景图分类(Scene graph classification): 给定图中目标位置,对关系及目标关系进行归类,记为 P(R, O | B, I)。
场景图生成(Scene graph generation): 只给定图片,要求生成 scene graph,记为 P( G={R, O, B} | I)。
前一个任务可认为是后一个任务简化版。在评测模型能力时,一般需要考察模型在此三个任务的表现,以评价模型中关系分类模块、目标分类模块及目标定位模块的作用。
数据集
Visual Genome 于2016年提出[1],是这个领域最常用的数据集,包含对超过 10W 张图片的目标、属性、关系、自然语言描述、视觉问答等的标注。与此任务相关的数据总结如下:
目标 or 图节点:用 bounding box 标注位置,并且有对应的类别名称。Visual Genome 包含约 17,000 种目标。
关系 or 图的边:可以动作 (jumping over),空间关系(on),从属关系(belong-to, has),动词(wear)等。Visual Genome 包含一共 13K 种关系。
属性(在图中附着在是节点上):可以实验颜色(yellow),状态(standing)等。Visual Genome 包含约 155000 种属性。
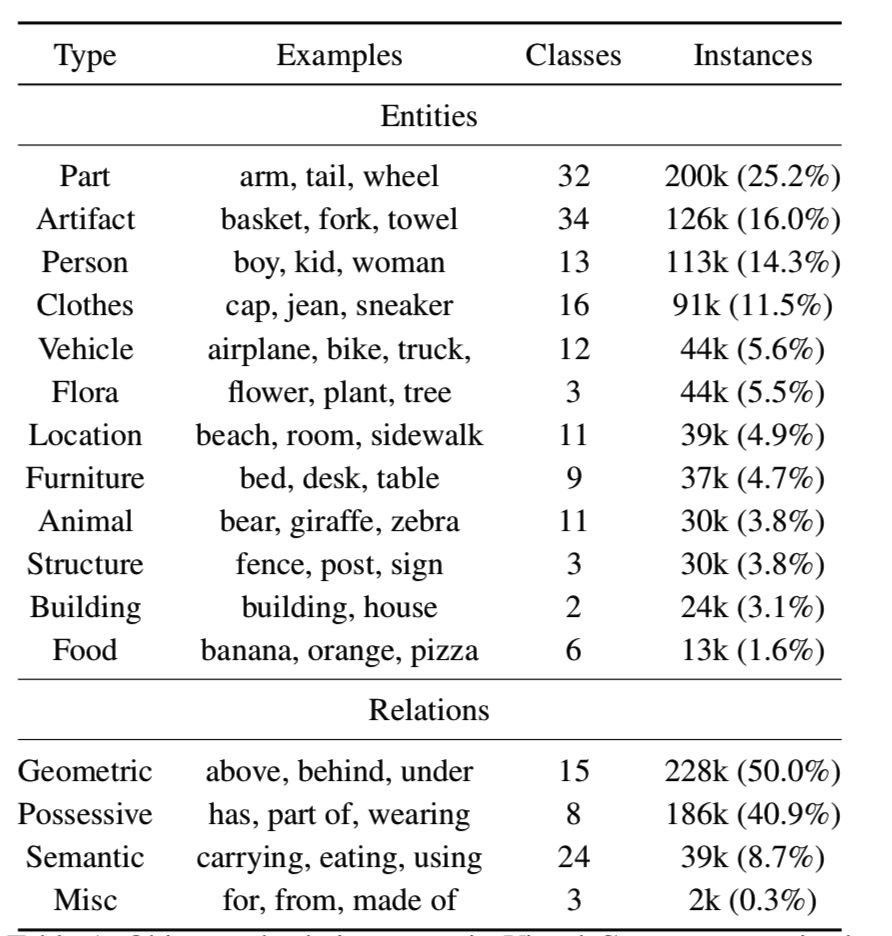
对于目标、关系、属性对应的字词,使用了 WordNet 进行规范化,目的是为了归并同义词。不过常用的只是 Visual Genome 的一个子集([3,4,5] 文献都用到这个子集,简称为 VG150),选取了150 种常见目标,50 种常见关系,统计详见下表[2], [3]。
方法分类
目前的大多数场景图生成模型,根据任务的分解大致分为如下两种:
- P(O,B,R | I) = P(O,B | I) * P(R| I,O,B),即先目标检测,再进行关系预测(有一个专门研究该子任务的领域,称为研究视觉关系识别,visual relationship detection)。最简单的方法是下文中基于统计频率的 baseline 方法,另外做视觉关系检测任务的大多数工作都可以应用到这里。
- P(O,B,R | I) = P(B | I) * P(R,O| I,O,B),即先定位目标,然后将一张图片中所有的目标和关系看做一个未标记的图结构,再分别对节点和边进行类别预测。这种做法考虑到了一张图片中的各元素互为上下文,为彼此分类提供辅助信息。接下来的 IMP、GRCNN 及 Neural Motif 中基于 RNN 的方法属于这一类。事实上,自此类方法提出之后 [2],才正式有了 scene graph generation 这个新任务名称(之前基本都称为 visual relationship detection)。
当前的挑战
最近从数据角度,发现该任务的几个棘手的问题。
- 关系简单。从表1看出,空间关系和从属关系占了所有标注的90%以上,语义关系只占很少部分。
- 关系类别不互斥。比如 on, sitting on。这使得同一对目标可能存在多个关系标注。视觉关系分类建模成“多选一”的分类问题是否合理,也需要深思。
- 关系整体分布长尾效应严重。一般而言,可以将视觉关系分为空间关系、从属关系和语义关系等几种。对每一种关系的画柱状图,可以看出长尾分布非常严重。
- 关系的条件分布 bias 问题严重。比如已知主语宾语是 person 和 head,基本就可以猜测关系是 person has head 或是无关系。这也导致用复杂模型来预测并不比盲猜好多少的现象。
- 标注稀疏。VG 数据集每个图片大致有10个标注目标,但只有不到5组关系标注。很多目标之间存在关系,但却没有标注。
这些问题不能完全归咎于数据集,很大程度上由任务本身决定,换数据集问题照样存在。还有毕竟重建数据集工作量巨大,也不能保证重新标注得多好。更聪明的做法或许是接受现实,从解决问题的方法上努力,比如引入半监督学习处理标注稀疏的问题 [10],或者引入因果推理处理 bias 问题 [5]。
参考
[1] J. Johnson et al., “Image retrieval using scene graphs,” in 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, Jun. 2015, pp. 3668–3678, doi: 10.1109/CVPR.2015.7298990.
[2] D. Xu, Y. Zhu, C. B. Choy, and L. Fei-Fei, “Scene Graph Generation by Iterative Message Passing,” p. 10, 2017.
[3] R. Zellers, M. Yatskar, S. Thomson, and Y. Choi, “Neural Motifs: Scene Graph Parsing with Global Context,” in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, Jun. 2018, pp. 5831–5840, doi: 10.1109/CVPR.2018.00611.
[4] S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 39, no. 6, pp. 1137–1149, 2017, doi: 10.1109/TPAMI.2016.2577031.
[5] K. Tang, Y. Niu, J. Huang, J. Shi, and H. Zhang, “Unbiased Scene Graph Generation from Biased Training,” ArXiv200211949 Cs, Mar. 2020, Accessed: Mar. 10, 2020. [Online]. Available: http://arxiv.org/abs/2002.11949.
[6] C. Lu, R. Krishna, M. Bernstein, and L. Fei-Fei, “Visual Relationship Detection with Language Priors,” ArXiv160800187 Cs, Jul. 2016, Accessed: Mar. 04, 2020. [Online]. Available: http://arxiv.org/abs/1608.00187.
[7] J. Yang, J. Lu, S. Lee, D. Batra, and D. Parikh, “Graph R-CNN for Scene Graph Generation,” ArXiv180800191 Cs, Aug. 2018, Accessed: Feb. 21, 2020. [Online]. Available: http://arxiv.org/abs/1808.00191.
[8] R. Krishna et al., “Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations,” ArXiv160207332 Cs, Feb. 2016, Accessed: Feb. 22, 2020. [Online]. Available: http://arxiv.org/abs/1602.07332.
[9] A. Zareian, S. Karaman, and S.-F. Chang, “Bridging Knowledge Graphs to Generate Scene Graphs,” ArXiv200102314 Cs, Jan. 2020, Accessed: Feb. 22, 2020. [Online]. Available: http://arxiv.org/abs/2001.02314.
[10] V. S. Chen, P. Varma, R. Krishna, M. Bernstein, C. Re, and L. Fei-Fei, “Scene graph prediction with limited labels,” in Proceedings of the IEEE International Conference on Computer Vision, 2019, pp. 2580–2590.