What makes for Good Views for Contrastive Learning?
论文来源:NeurIPS 2020
论文链接:https://arxiv.org/pdf/2005.10243v3.pdf
代码链接:https://github.com/HobbitLong/PyContrast
这篇文章主要提出了, 在对比学习中,我们在追求特征表示能够学到更多的相同类之间的共同特征时(InfoMax Principle),也应该针对下游任务,去掉会影响下游任务的冗余特征(InfoMin Principle)。
三个定义
Sufficient Encoder
在两个 view $v_i,v_2$ 之间进行 contrastive learning. 假设 $f_1$ 是 $v_1$ 的特征提取器,最终的特征表示为$z_1=f_1(v_1),z_2=f_2(v_2)$如果 $I(v_1,v_2)=I(f_1(v_1),v_2)$ ,则表示在编码过程中$v_1$关于$v_2$的信息没有损失。 换一句话说就是$z_1$中保留了对比学习所需要的所有信息。这就表明$f_1$是充分的。同理当$I(v_1,v_2)=I(v_1,f_2(v_2))$时,$f_2$是充分的。
Minimal Sufficient Encoder
在上面 InfoMax 的基础上,加入 InfoMin 的含义。 $v_1$ 的编码器 $f_{min}$ 是最小的 sufficient encoder 当且仅当对于所有的 sufficient encoder $f$ , 有 $I(f_{min}(v_1),v_2) \leq I(f(v_1),v_2)$ 。因此 $f_{min}$ 是所有的 sufficient encoder 中含有信息量最小的一个。从理论上看,如果一个 encoder 能够保留足够的信息且含有最小的冗余,则该编码器具有更好的泛化能力。
Optimal Representation of a Task
将最大化两个 view 互信息的任务扩展到一个预测任务 $\tau$ . 根据输入数据 $x$ 来预测 $y$ . 则关于 $x$ 的最优表示 $z^{}$ 是关于 $y$ 的一个 minimal sufficient encoder. 意思是 $z^{}$ 中包含了 $x$ 中所有关于 $y$ 的信息,同时尽可能少的包含其他冗余信息。
Colorful-Moving-Mnist
构造了一组数据集。构造两个 view 之前共享的信息分别为 (1) ”position“( $x_t$ 和 $v_2^+$ 中数字不同,背景不同,但是数字的位置相同),(2)”digit” ( $x_t$ 和 $v_2^+$ 中数字一致,其余信息都不同),(3)”background”(同理,仅background相同)。同时构造负样本 $v_2^-$ 。
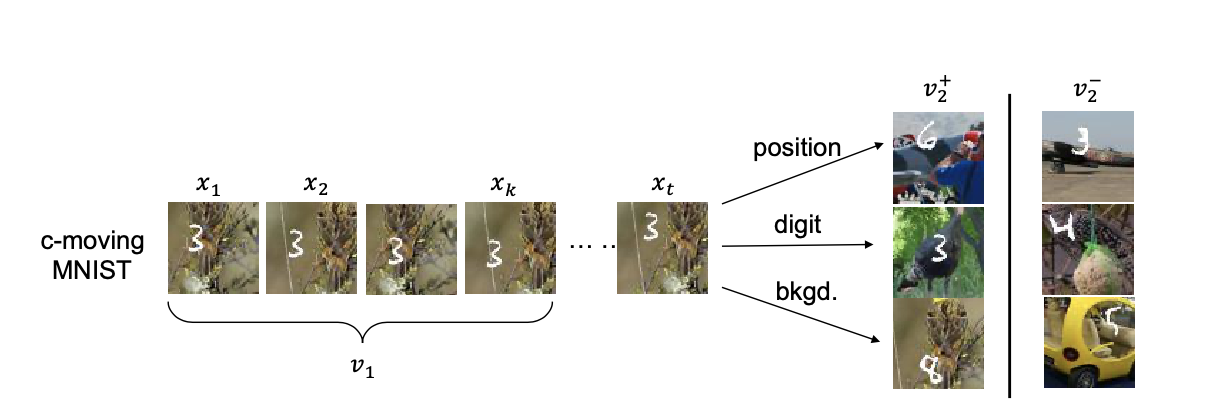
通过人为构造的数据集,可以控制两个 view 之间共享的变量。如共享 position,共享 digit,或者同时共享其中两者等。如下表,在每一对人为设置的共享变量的 view 中进行 contrastive learning,在不同的下游任务中进行评价。
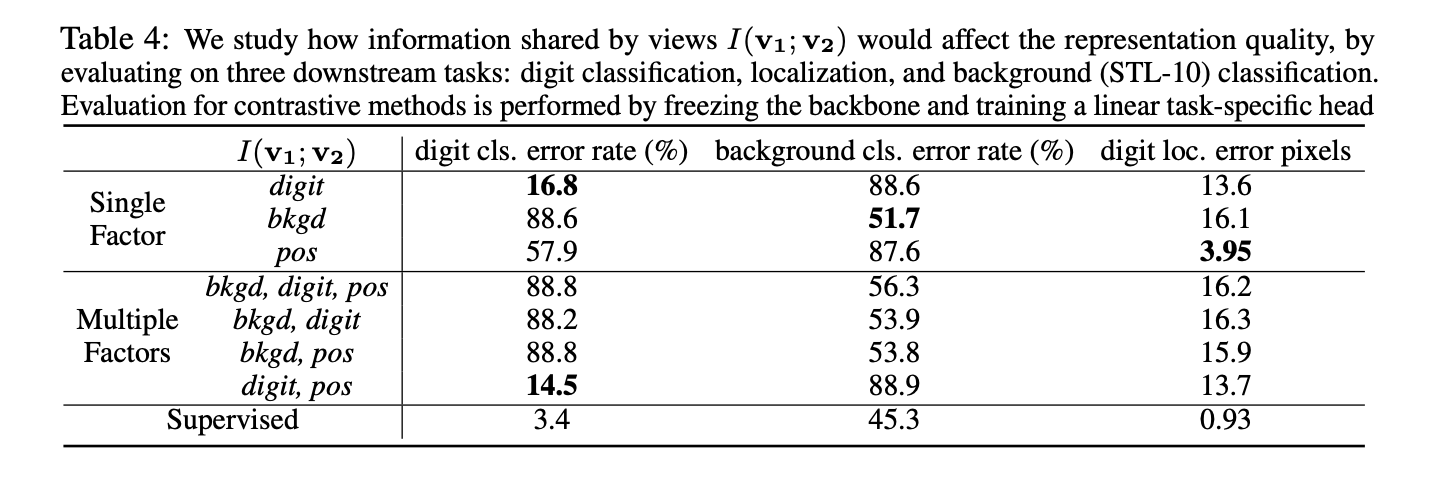
从该表的结果中可以得出以下结论:
不同 view 之间共享的信息对下游任务的影响很大。例如,如果只共享 digit 的部分,那么特征表示会忽略 background 和 location 的信息,因此在这两个任务中无法取得效果。如果仅共享 background 的部分,那么关于 digit 分类和 location 无法成功。
当共享多个信息时,往往其中一个信息会占据主导地位。如共享 digit 和 position 时,digit 占据了主导地位,原因可能是因为 convolution 本来对 position 不敏感。当有 background 作为两个 view 之间共享因素时,background 往往会占据主导,其他任务都无法取得好的效果。
假设 $v_1,v_2$ 是原始数据 $x$ 的两个 view, 最大化 $v_1,v_2$ 的 mutual-information $I(v_1,v_2)$ 目的是提取原始数据 $x$ 中与任务 $y$ 有关的信息 $I(x,y)$ 。其中,$I(x,y)$ 在给定数据和学习目标下是一个固定的值。下图给出了在最大化 $I(v_1,v_2)$ 的过程中和 $I(x,y)$ 之间的关系图。

学习分为三个阶段:
开始时 $I(v_1,v_2)<I(x,y)$ ,特征表示中没有包含足够的信息来预测 $y$ 。
在学习过程中到达一个 sweet spot,其中 $I(v_1,v_2)=I(x,y)$ , 表明 $v_1,v_2$ 中 share 的信息量等价于数据和 label 之间的信息量。此时特征表示包含了所有的预测有关的信息,同时没有包含冗余的信息。
随后 $I(v_1,v_2)>I(x,y)$ , 特征表示开始包含冗余的信息。
在InfoMax的过程中,仅当到达中间的 sweet spot 时:
- 在当前任务中具有能够预测目标 $y$ 的信息;
- 是一个 minimal sufficient encoder,具有最好的泛化能力。
在分类任务中验证上面的想法。原始数据是图像,其中 $v_1,v-2$ 是相隔 $d$ 个像素位置提取的 patch,通过最大化 $v_1,v_2$ 的互信息来提取特征。任务 $y$ 是分类任务,在提取的特征基础上用 linear 层进行分类。可以看到,随着 pitch distance 的增大(图中从右到左),mutual-information 不断减小,在中间达到了一个 sweet spot,对下游任务具有最大的泛化能力。
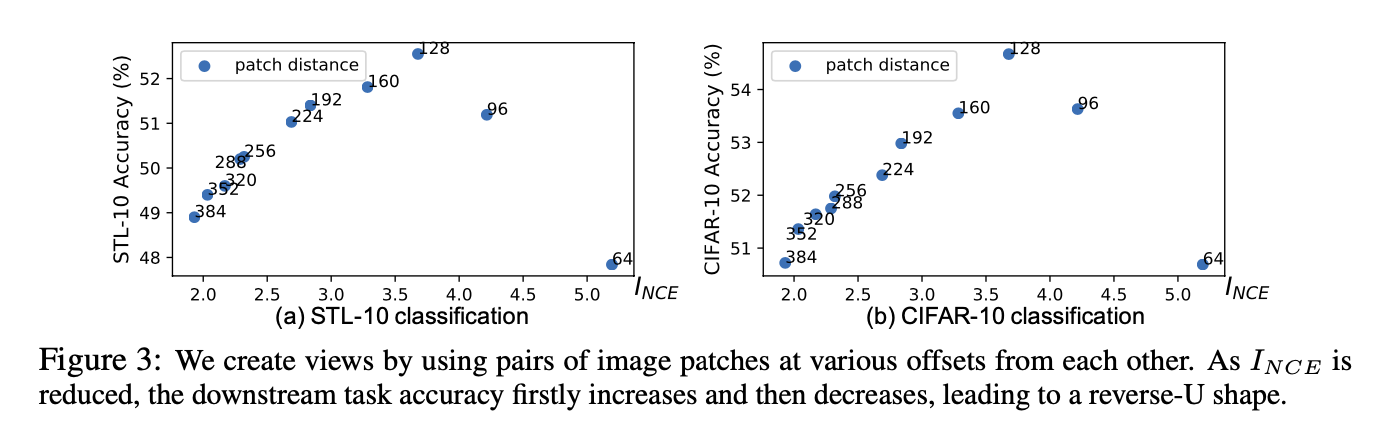
Data Augmentation
在产生 view 的 augmentation 层面可以显示 $v_1,v_2$ 的互信息。具体的,施加的augmentation越大,会导致 $v_1,v_2$ 的互信息越小,但可在后续的分类任务中产生更好的性能。
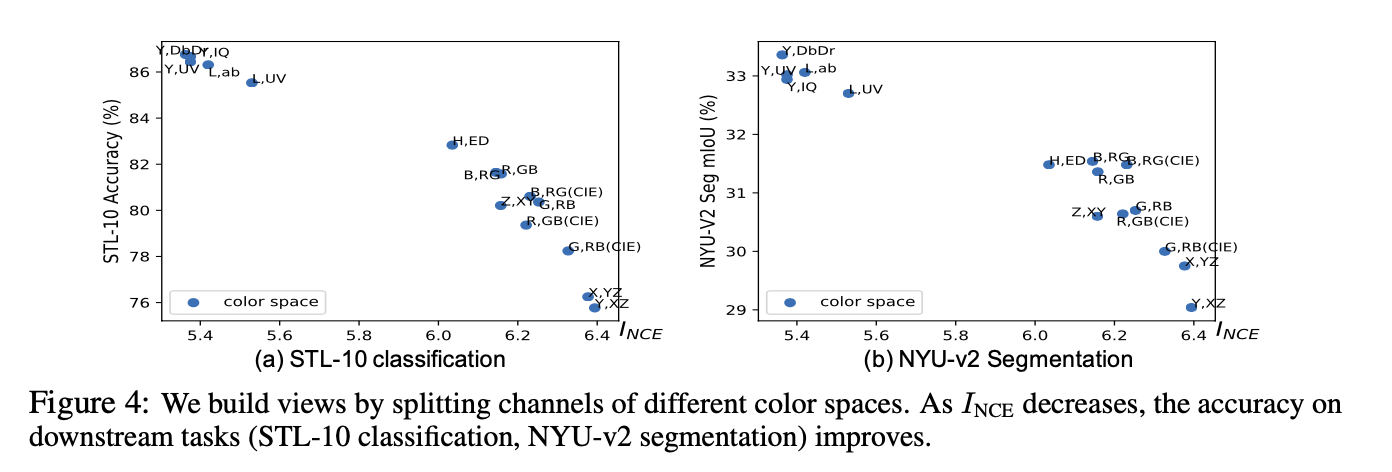
Synthesizing Views with Invertible Generators
本文提出了一种 adversarial training 的方法来获得 minimal sufficient encoder. 在原来对两个 view 的两个编码器 $f_1,f_2$ 的基础上增加一个编码器 $g$ ,先使用 $g$ 分别对两个 view $X_1,X_2$ 进行编码得到 $\hat{X_1},\hat{X_2}$ , 随后再使用 $f_1,f_2$ 两个 encoder 来最大化互信息,学习目标为:
Unsupervised View Learning
Minimize $I(v_1, v_2)$
Semi-supervised View Learning
Find Views that Share the Label Information
其中 $g$ 的学习目标是 adversarial 的,最小化互信息。在对抗训练中希望得到 minimal sufficient 表示。