Pytorch-Batch_first的理解
用过PyTorch的朋友大概都知道,对于不同的网络层,输入数据的维度虽然不同,但是通常第一维都是batch_size。
比如torch.nn.Linear的输入$(batch_size, *, in_features)$,torch.nn.Conv2d的输入$(batch_size, C_{in}, H_{in} , W_{in} )$。
而RNN的输入却是$(seq_len, batch_size, input_size)$,batch_size位于第二维度!虽然你可以将batch_size和序列长度seq_len对换位置,此时只需要把参数batch_first设置为True。但是默认情况下RNN输入为啥不是batch first?
原因同上,因为cuDNN中RNN的API就是batch_size在第二维度!进一步,为啥cuDNN要这么做呢?
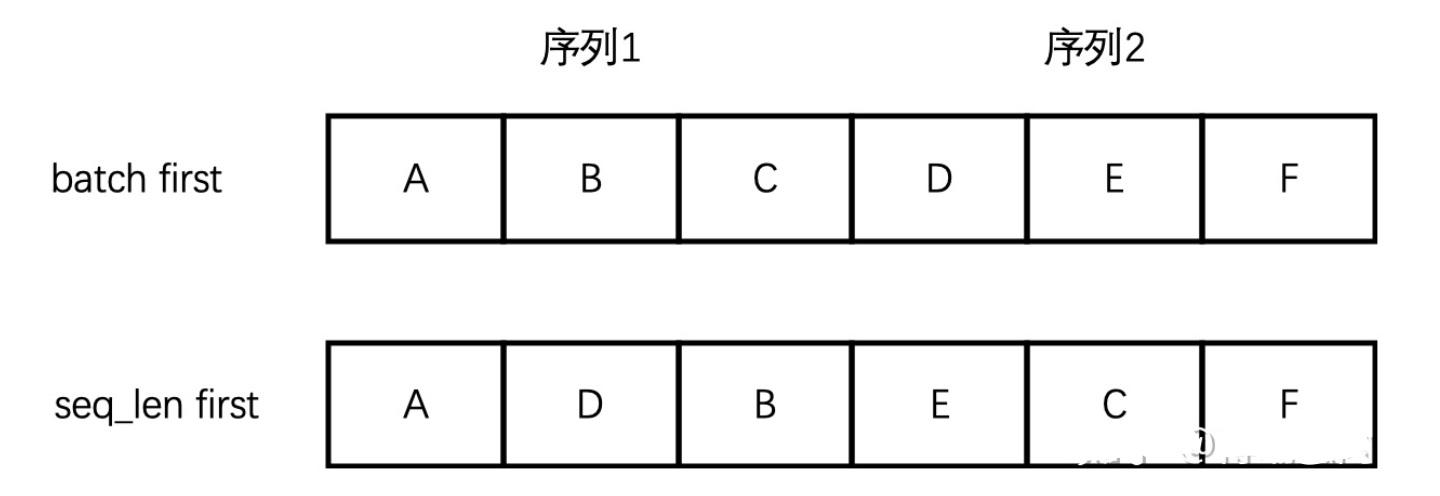
举个例子,假设输入序列的长度(seq_len)是3,batch_size是2,一个batch的数据是[[“A”, “B”, “C”], [“D”, “E”, “F”]],如下图所示。
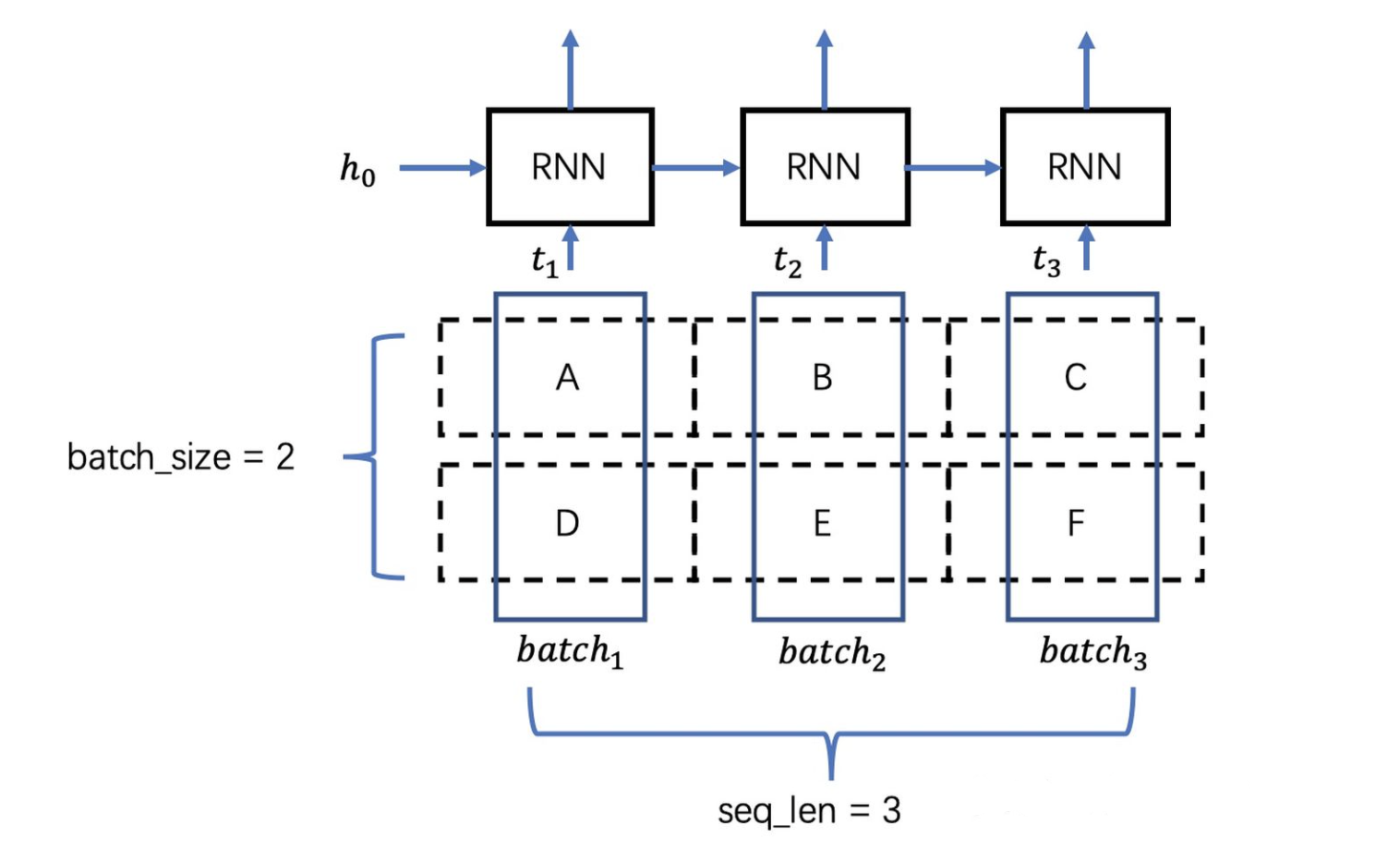
由于RNN是序列模型,只有 $t_1$ 时刻计算完成,才能进入 $t_2$ 时刻,而”batch”就体现在每个时刻 $t_i$ 的计算过程中,上图中 $t_i$ 时刻将[“A”, “D”]作为当前时刻的batch数据,$t_2$ 时刻将[“B”, “E”]作为当前时刻的batch数据,可想而知,”A”与”D”在内存中相邻比”A”与”B”相邻更合理,这样取数据时才更高效。而不论Tensor的维度是多少,在内存中都以一维数组的形式存储,batch first意味着Tensor在内存中存储时,先存储第一个sequence,再存储第二个… 而如果是seq_len first,模型的输入在内存中,先存储所有sequence的第一个元素,然后是第二个元素… 两种区别如图2所示,seq_len first意味着不同sequence中同一个时刻对应的输入元素(比如”A”, “D” )在内存中是毗邻的,这样可以快速读取数据。