什么事激活函数?
神经网络中的每个神经元节点接受上一层神经元的输出值作为本神经元的输入值,并将输入值传递给下一层,输入层神经元节点会将输入属性值直接传递给下一层(隐层或输出层)。在多层神经网络中,上层节点的输出和下层节点的输入之间具有一个函数关系,这个函数称为激活函数(又称激励函数)。
激活函数有什么用?
如果不用激励函数(其实相当于激励函数是f(x) = x),在这种情况下你每一层节点的输入都是上层输出的线性函数,很容易验证,无论你神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(Perceptron)了,那么网络的逼近能力就相当有限。正因为上面的原因,我们决定引入非线性函数作为激励函数,这样深层神经网络表达能力就更加强大(不再是输入的线性组合,而是几乎可以逼近任意函数)。
常见激活函数
常见的激活函数有:
Sigmoid激活函数
Tanh激活函数
Relu激活函数
Leaky Relu激活函数
P-Relu激活函数
ELU激活函数
R-Relu激活函数
Gelu激活函数
swich激活函数
Selu激活函数
激活函数可以分为两大类 :
饱和激活函数:sigmoid、tanh
非饱和激活函数: ReLU、Leaky Relu、ELU【指数线性单元】、PReLU【参数化的ReLU 】、RReLU【随机ReLU】
Sigmoid
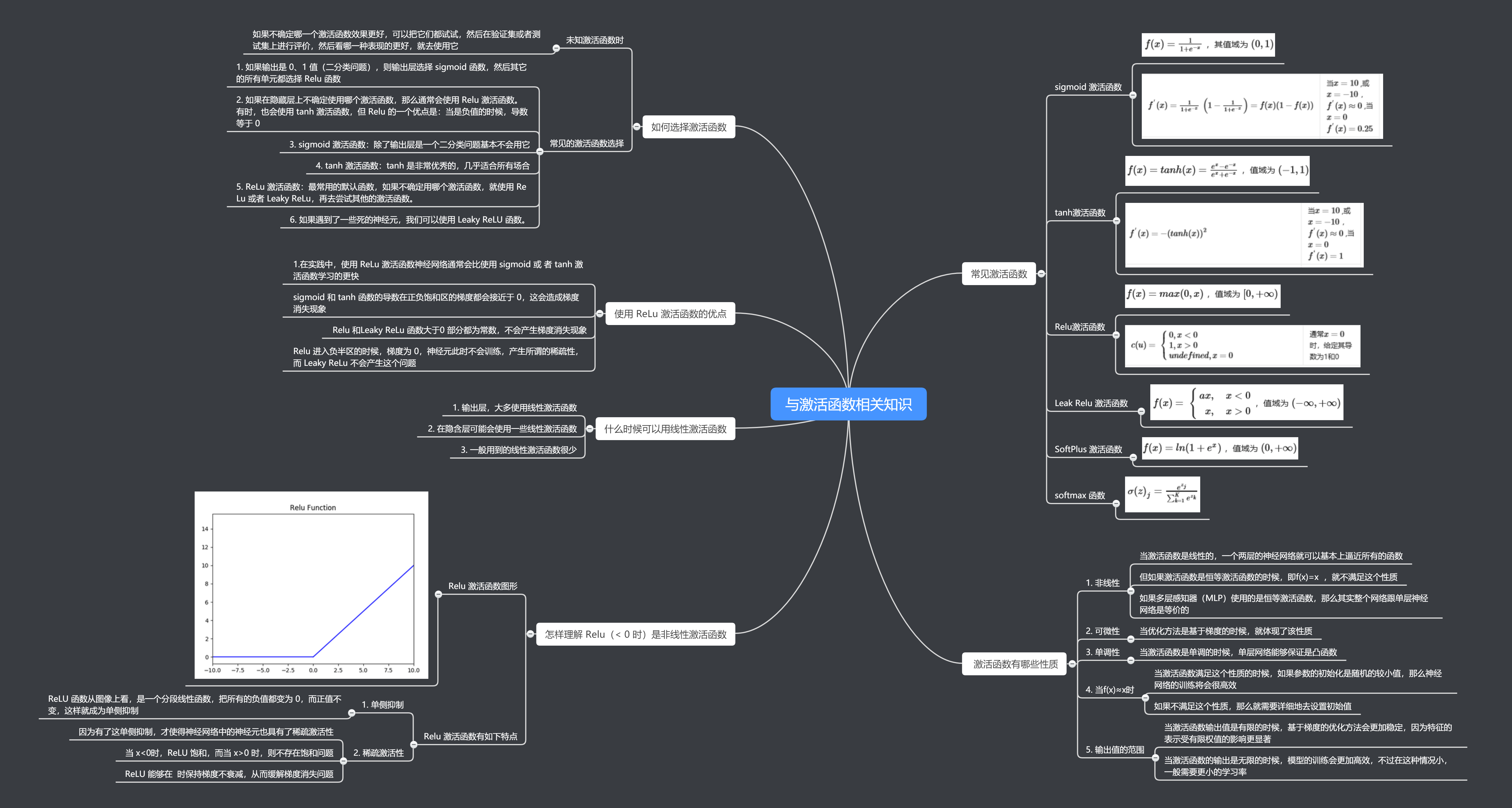
sigmoid函数也叫Logistic函数,用于隐藏层的输出,输出在(0,1)之间,它可以将一个实数映射到(0,1)的范围内,可以用来做二分类。常用于:在特征相差比较复杂或是相差不是特别大的时候效果比较好。该函数将大的负数转换成0,将大的正数转换为1。公式描述如下:
函数图像:
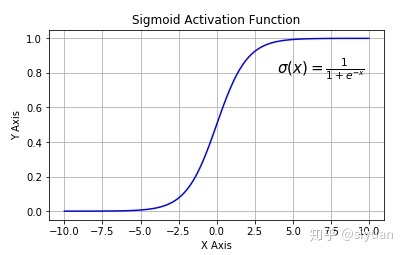
导数图像:
缺点:
梯度消失:Sigmoid 函数趋近 0 和 1 的时候变化率会变得平坦,也就是说,Sigmoid 的梯度趋近于 0。神经网络使用 Sigmoid 激活函数进行反向传播时,输出接近 0 或 1 的神经元其梯度趋近于 0。这些神经元叫作饱和神经元。因此,这些神经元的权重不会更新。此外,与此类神经元相连的神经元的权重也更新得很慢。该问题叫作梯度消失。因此,想象一下,如果一个大型神经网络包含 Sigmoid 神经元,而其中很多个都处于饱和状态,那么该网络无法执行反向传播。
Sigmoid 的 output 不是0均值(即zero-centered)。这会导致后一层的神经元将得到上一层输出的非0均值的信号作为输入。
计算成本高昂:exp() 函数与其他非线性激活函数相比,计算成本高昂。
Tanh
Tanh 激活函数又叫作双曲正切激活函数(hyperbolic tangent activation function)。
函数及导数图像:
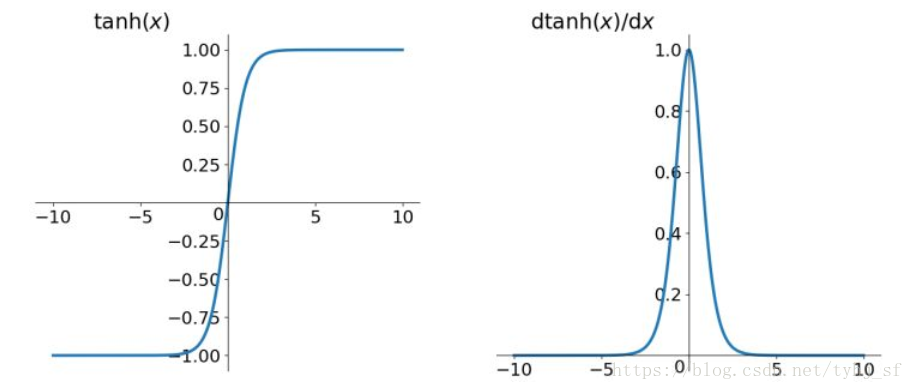
与 Sigmoid 函数类似,Tanh 函数也使用真值,但 Tanh 函数将其压缩至-1 到 1 的区间内。与 Sigmoid 不同,Tanh 函数的输出以零为中心,因为区间在-1 到 1 之间。你可以将 Tanh 函数想象成两个 Sigmoid 函数放在一起。在实践中,Tanh 函数的使用优先性高于 Sigmoid 函数。负数输入被当作负值,零输入值的映射接近零,正数输入被当作正值。
优点:它解决了Sigmoid函数的不是zero-centered输出问题。
缺点:梯度消失(gradient vanishing)的问题和幂运算的问题仍然存在。
Relu
函数及导数图像:
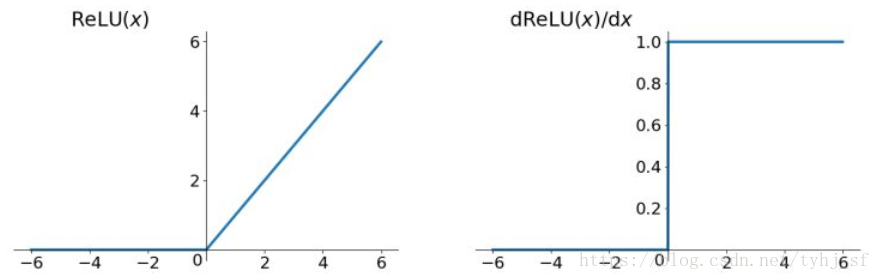
Relu是个分段线性函数,显然其导数在正半轴为1,负半轴为0,这样它在整个实数域上有一半的空间是不饱和的。相比之下,sigmoid函数几乎全部区域都是饱和的.
ReLU虽然简单,但却是近几年的重要成果,有以下几大优点:
- 解决了gradient vanishing问题 (在正区间)
- 计算速度非常快,只需要判断输入是否大于0
- 收敛速度远快于sigmoid和tanh
ReLu是分段线性函数,它的非线性性很弱,因此网络一般要做得很深。但这正好迎合了我们的需求,因为在同样效果的前提下,往往深度比宽度更重要,更深的模型泛化能力更好。所以自从有了Relu激活函数,各种很深的模型都被提出来了,一个标志性的事件是应该是VGG模型和它在ImageNet上取得的成功.
ReLU也有几个需要特别注意的问题:
- ReLU的输出不是zero-centered
- 某些神经元可能永远不会被激活(Dead ReLU Problem),导致相应的参数永远不能被更新。
有两个主要原因可能导致这种情况产生:
非常不幸的参数初始化,这种情况比较少见
learning rate太高导致在训练过程中参数更新太大,不幸使网络进入这种状态。解决方法是可以采用Xavier初始化方法,以及避免将learning rate设置太大或使用adagrad等自动调节learning rate的算法。
Leaky Relu
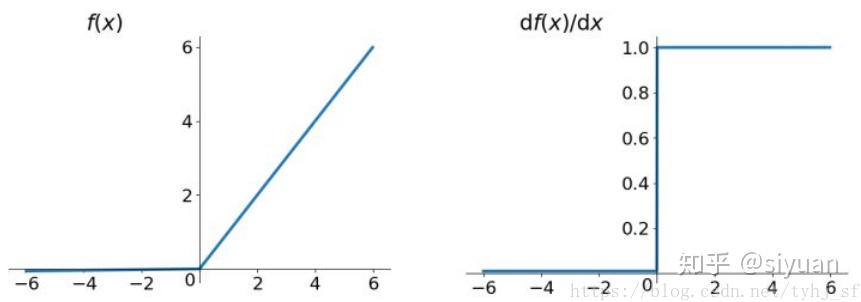
Leaky ReLU 的概念是:当 x < 0 时,它得到 0.01 的正梯度。
优点:
该函数一定程度上缓解了 dead ReLU 问题。
缺点:
使用该函数的结果并不连贯。尽管它具备 ReLU 激活函数的所有特征,如计算高效、快速收敛、在正区域内不会饱和。
P-Relu(Parametric ReLU)
其中$\alpha$为可学习参数。
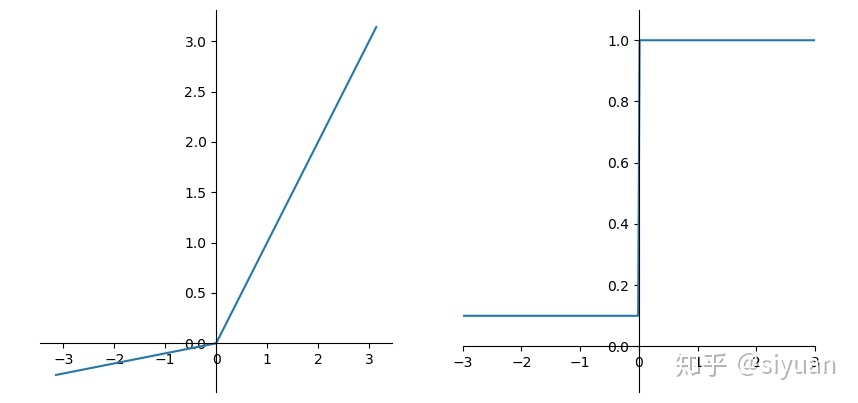
这里引入了一个随机的超参数 $\alpha$ ,它可以被学习,因为你可以对它进行反向传播。这使神经元能够选择负区域最好的梯度,有了这种能力,它们可以变成 ReLU 或 Leaky ReLU。
总之,最好使用 ReLU,但是你可以使用 Leaky ReLU 或 Parametric ReLU 实验一下,看看它们是否更适合你的问题。
Elu
函数及导数图像:
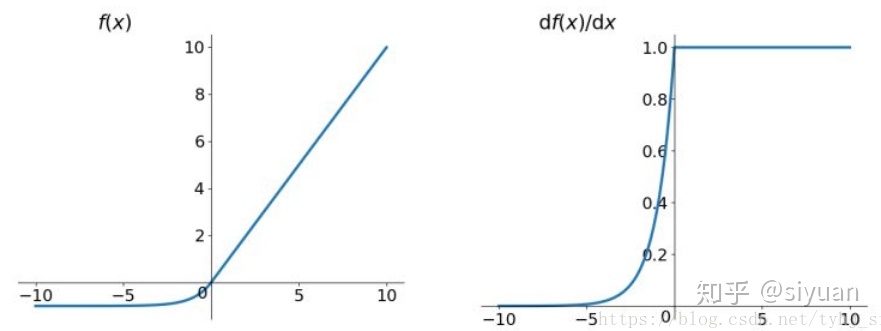
ELU也是为解决ReLU存在的问题而提出。
Elu激活函数有优点:ReLU的基本所有优点、不会有Dead ReLU问题,输出的均值接近0、零中心点问题。
Elu激活函数有缺点:计算量稍大,原点不可导。
类似于Leaky ReLU,理论上虽然好于ReLU,但在实际使用中目前并没有好的证据ELU总是优于ReLU。
Gelu
函数及导数图像:
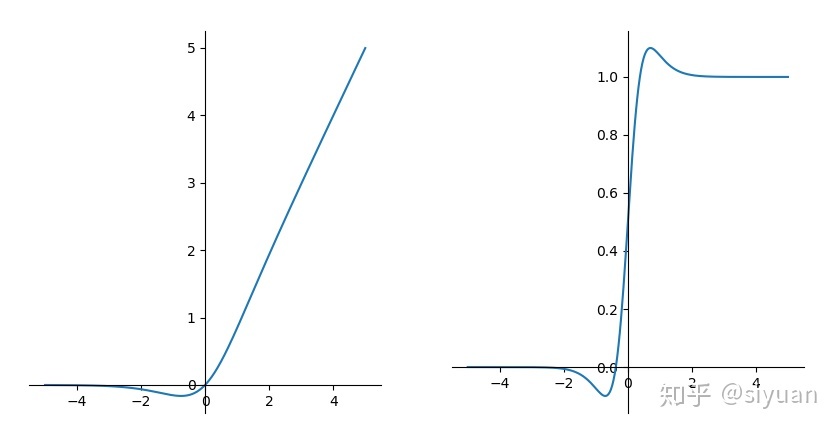
bert中使用的激活函数,作者经过实验证明比relu等要好。原点可导,不会有Dead ReLU问题。值得注意的是最近席卷NLP领域的BERT等预训练模型几乎都是用的这个激活函数。
Swich
函数及导数图像:
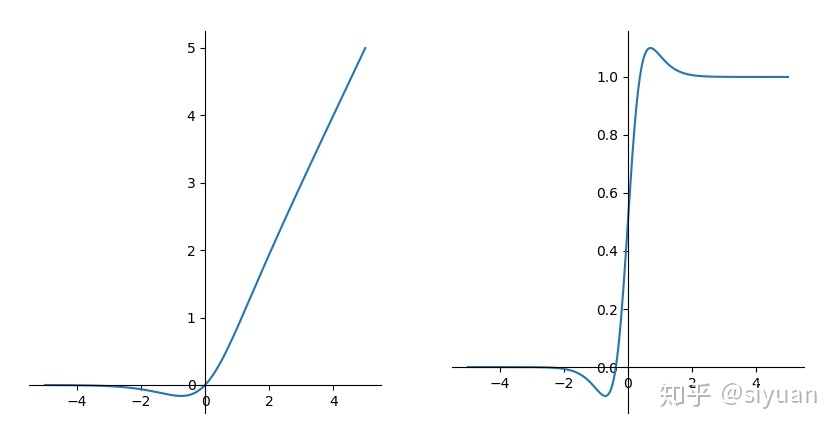
根据上图,从图像上来看,Swish函数跟ReLu差不多,唯一区别较大的是接近于0的负半轴区域,因此,Swish 激活函数的输出可能下降,即使在输入值增大的情况下。大多数激活函数是单调的,即输入值增大的情况下,输出值不可能下降。而 Swish 函数为 0 时具备单侧有界(one-sided boundedness)的特性,它是平滑、非单调的。
缺点: - 只有实验证明,没有理论支持。 - 在浅层网络上,性能与relu差别不大。
Selu
其实就是ELU乘了个lambda,关键在于这个lambda是大于1的。以前relu,prelu,elu这些激活函数,都是在负半轴坡度平缓,这样在activation的方差过大的时候可以让它减小,防止了梯度爆炸,但是正半轴坡度简单的设成了1。而selu的正半轴大于1,在方差过小的的时候可以让它增大,同时防止了梯度消失。这样激活函数就有一个不动点,网络深了以后每一层的输出都是均值为0方差为1。
当其中参数取为$\lambda \approx 1.0506, \alpha \approx 1.6733$时,在网络权重服从标准正态分布的条件下,各层输出的分布会向标准正态分布靠拢。这种「自我标准化」的特性可以避免梯度消失和爆炸的问题,让结构简单的前馈神经网络获得甚至超越 state-of-the-art 的性能。
selu的证明部分前提是权重服从正态分布,但是这个假设在实际中并不能一定成立,众多实验发现效果并不比relu好。