A new method of region embedding for text classification
论文来源:ICLR 2018
论文链接:https://openreview.net/references/pdf?id=ByD5LekDM
代码链接:https://github.com/text-representation/local-context-unit
传统的bag-of-words方法虽然能够有效的训练出词向量,不过却损失了重要的单词顺序信息。
之后提出的n-grams,虽然有用,但是也有一定的局限性:
- n-grams的数量会随着n的增加爆炸式增长。
- n-grams模型中的参数非常多,这会导致数据稀疏的问题。
于是作者就提出了一种新的n-gram embedding方法叫做 region embedding。
方法
$region(i,c)$ 表示以单词$w_i$为中心,向左右延伸$c$个单词,长度为$2*c+1$的区域。
在作者的模型中,一个单词的嵌入由两部分组成。$e_{w_i} \in ℝ^{h×1}$ 和 $K_{w_i}\in ℝ^{h×(2×c+1)}$。
$e_{w_i}$表示单词$w_i$的词嵌入向量。 $K_{w_i}$表示单词$w_i$的上下文单元。
模型中
所有的$e_{w_i}$用矩阵$E \in ℝ^{h×v}$, $v$表示字典大小。$h$表示词嵌入的大小。
所有的$K_{w_i}$用$U\inℝ^{h×(2×c+1)×v}$表示。
之后使用$E和U$计算出$P$。
$p_{w_{i+t}}^i = K_{w_i,t}⊙e_{w_{i+t}}$
这里的$⊙$表示按元素乘。
这里的计算方法有两种,具体如下图所示:
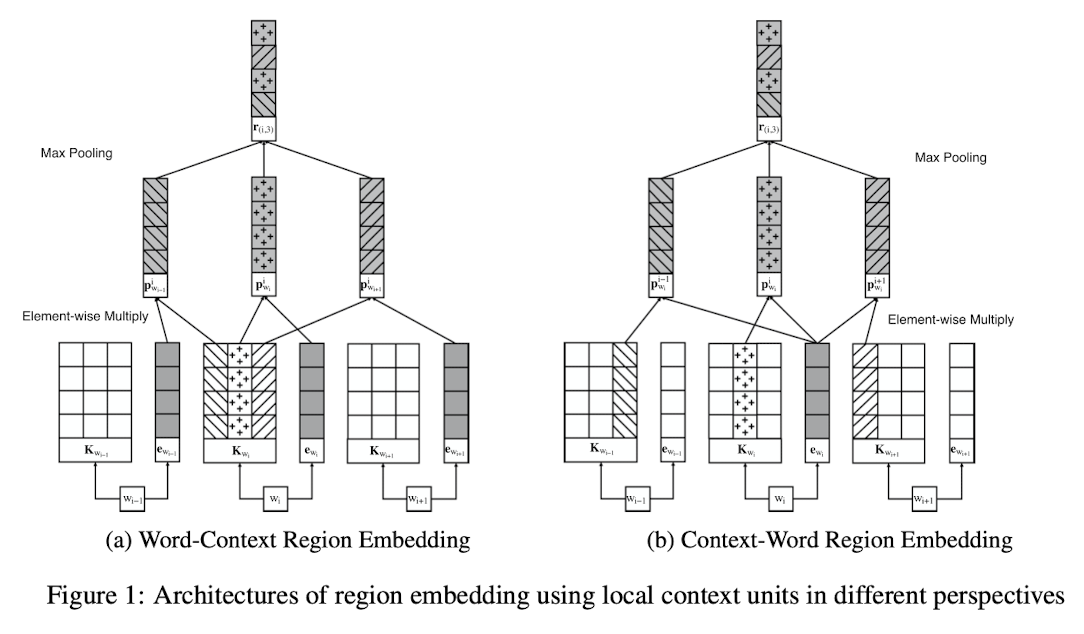
然后对P进行最大池化得到区域嵌入。
Word-Context Region Embedding
Context-Word Region Embedding
之后在使用region embedding 进行分类预测。