Explicit Interaction Model towards Text Classification
论文来源:AAAI 2019
论文链接:https://arxiv.org/abs/1811.09386
代码链接:https://github.com/NonvolatileMemory/AAAI_2019_EXAM
该文章的 idea 和之前的几篇类似,文本分类中没有充分利用 label 信息的问题,也都指出了对 label 做 encoding 的方法,作者提出了一个新的框架 EXplicit interAction Model (EXAM),加入了 interaction mechanism。
概述
如下图所示,传统分类的解决方案通过 dot-product 操作 将文本级表示与 label 表示匹配。 在数学上,FC 层的参数矩阵可以解释为一组类表示(每个列与一个类关联)。
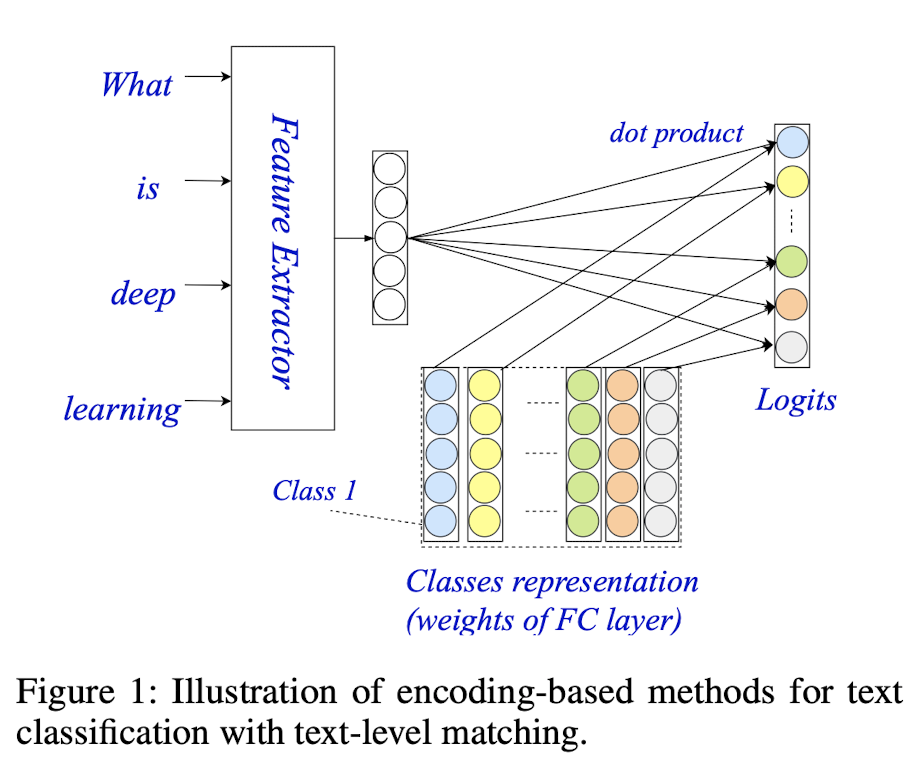
因此,文本属于某个类的概率在很大程度上取决于其整体匹配得分,而与单词级匹配信号无关,单词级匹配信号会为分类提供明确的信号(例如,missile 强烈暗示了军事的主题)。
针对上述情况,作者引入了交互机制,该机制能够将单词级匹配信号纳入文本分类中。交互机制背后的关键思想是显式计算单词和类之间的匹配分数。从单词级别的表示中,它会计算一个交互矩阵,其中每个条目是单词和类(dot-product)之间的匹配得分。
模型
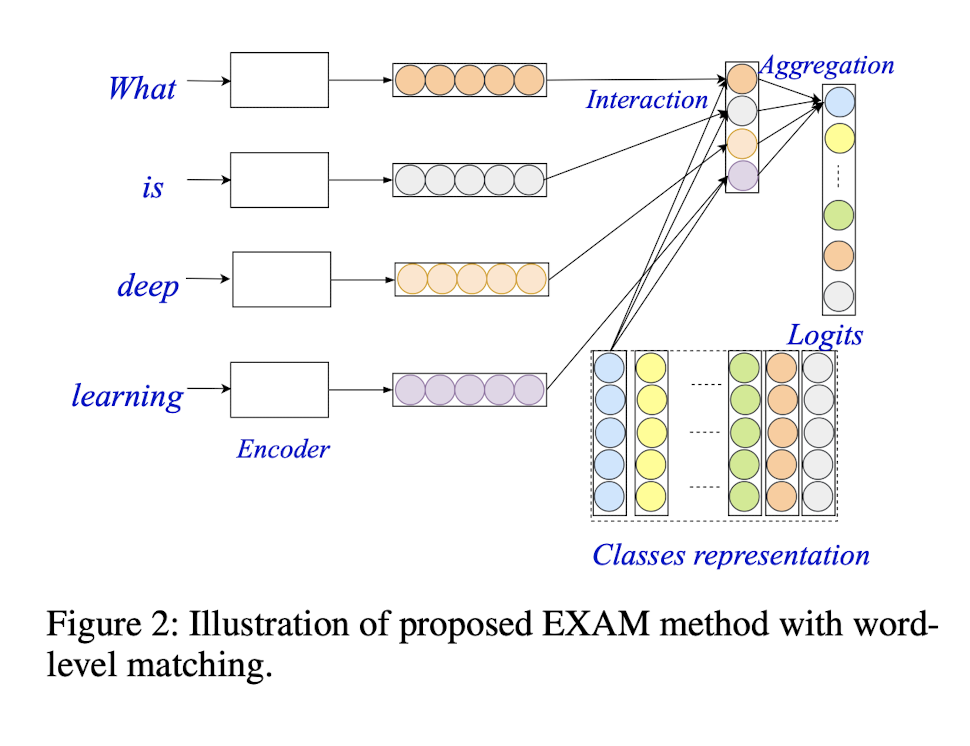
字级编码器(Encoder)
用于将输入文本 $d_i$ 投影到字级表示 $H$。
Gated Recurrent Unit
Region Embedding 来学习和利用 Ngrams 的任务特定的分布式表示。
交互层(Interaction)
用于计算单词和类之间的交互信号的交互层。

聚合层(Aggregation)
用于聚合每个类的交互信号并进行最终预测。
该层的设计目的是将每个类的交互特性聚合到一个 logits 中,表示类与输入文本之间的匹配分数。聚合层可以通过不同的方式实现,如 CNN 和 LSTM。但是,为了保持考试的简单性和效率,这里作者只使用了一个具有两个 FC 层的 MLP,其中 ReLU 被用作第一层的激活函数。在形式上,MLP对类的交互特性进行聚合,并计算其关联 logits 如下:

Loss(Cross Entropy)
