Attention Is All You Need
论文来源:NIPS 2017
论文链接:https://arxiv.org/pdf/1706.03762.pdf
代码链接:https://github.com/pytorch/fairseq
Attention Is All You Need,提出了一个只基于attention的结构来处理序列模型相关的问题,比如机器翻译。传统的神经机器翻译大都是利用RNN或者CNN来作为encoder-decoder的模型基础,而谷歌最新的只基于Attention的Transformer模型摒弃了固有的定式,并没有用任何CNN或者RNN的结构。该模型可以高度并行地工作,所以在提升翻译性能的同时训练速度也特别快。
作者采用Attention机制的原因是考虑到RNN(或者LSTM,GRU等)的计算限制为是顺序的,也就是说RNN相关算法只能从左向右依次计算或者从右向左依次计算,这种机制带来了两个问题:
时间片 $t$ 的计算依赖 $t-1$ 时刻的计算结果,这样限制了模型的并行能力;
顺序计算的过程中信息会丢失,尽管LSTM等门机制的结构一定程度上缓解了长期依赖的问题,但是对于特别长期的依赖现象,LSTM依旧无能为力。
Transformer的提出解决了上面两个问题,首先它使用了Attention机制,将序列中的任意两个位置之间的距离是缩小为一个常量;其次它不是类似RNN的顺序结构,因此具有更好的并行性,符合现有的GPU框架。论文中给出Transformer的定义是:Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence aligned RNNs or convolution。
Transformer结构示意图
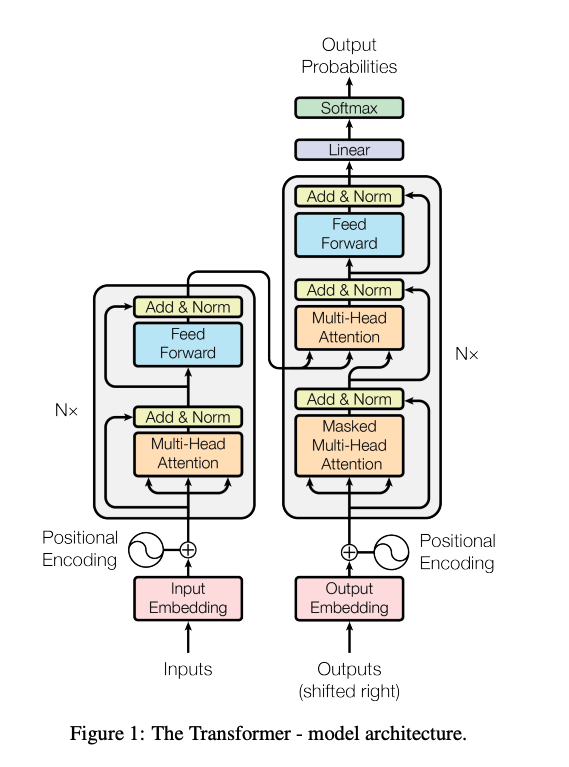
Transformer详解
高层Transformer
论文中的验证Transformer的实验室基于机器翻译的,下面我们就以机器翻译为例子详细剖析Transformer的结构,在机器翻译中,Transformer可概括为如图1:
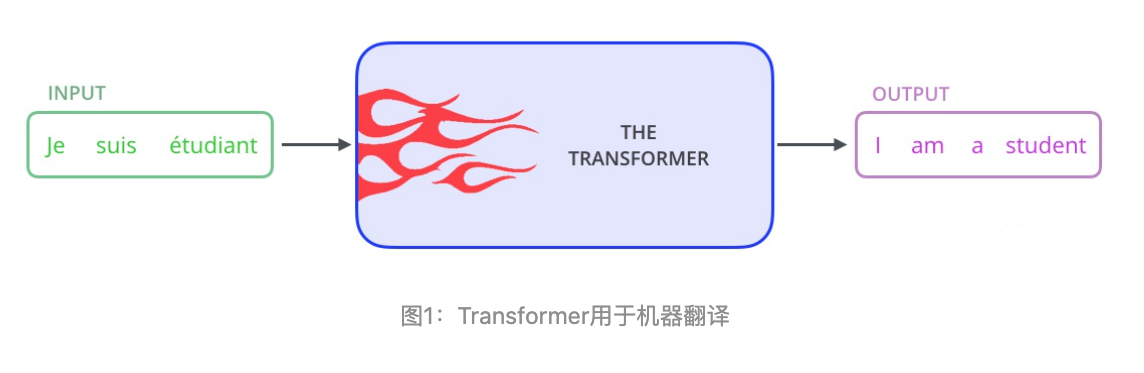
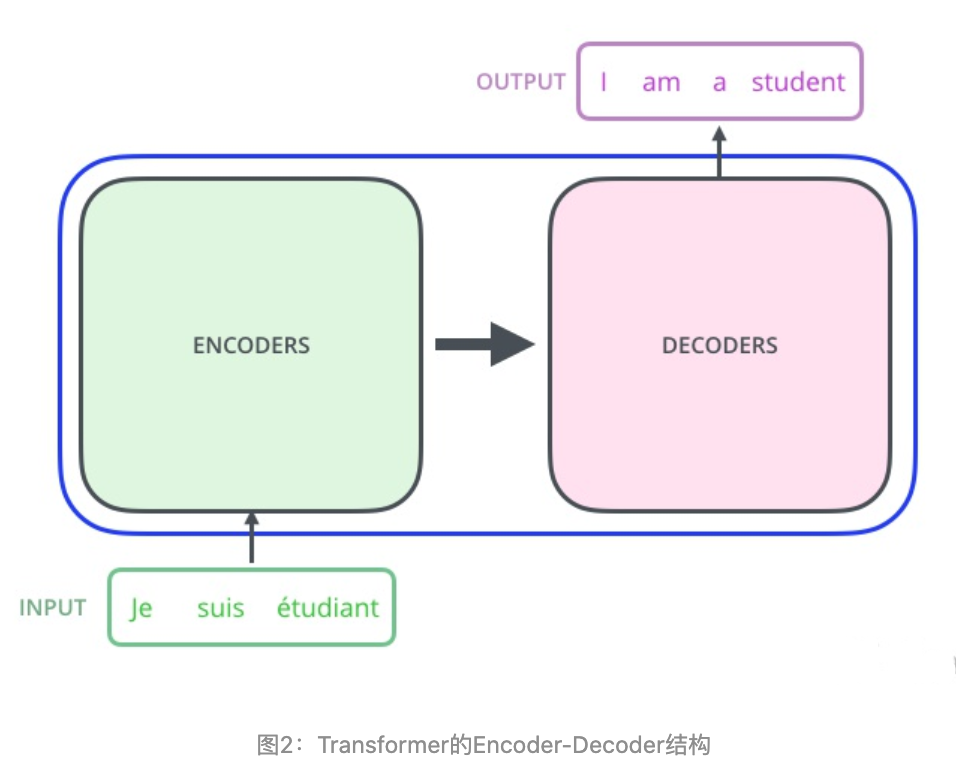
Transformer的本质上是一个Encoder-Decoder的结构,那么图1可以表示为图2的结构:
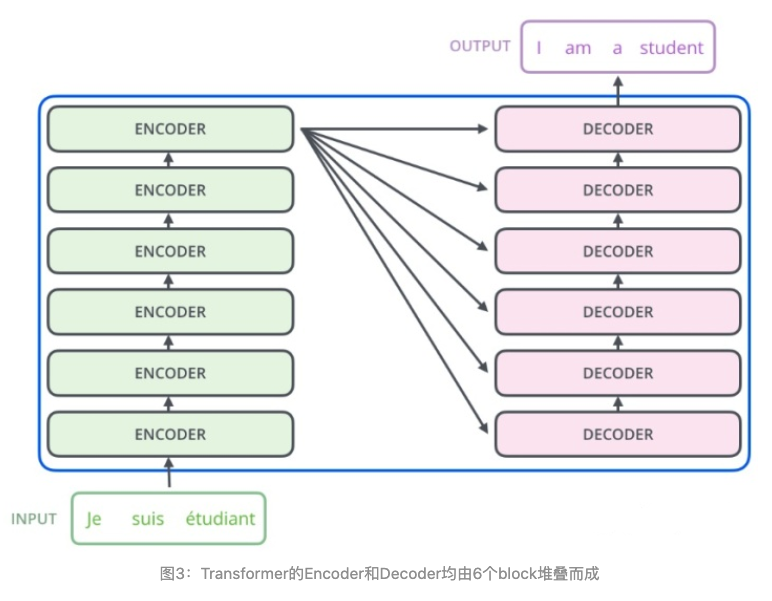
如论文中所设置的,编码器由6个编码block组成,同样解码器是6个解码block组成。与所有的生成模型相同的是,编码器的输出会作为解码器的输入,如图3所示:
我们继续分析每个encoder的详细结构:在Transformer的encoder中,数据首先会经过一个叫做‘self-attention’的模块得到一个加权之后的特征向量 $Z$ ,这个 $Z$ 便是论文公式1中的 $Attention(Q,K,V)$ :
第一次看到这个公式你可能会一头雾水,在后面的文章中我们会揭开这个公式背后的实际含义,在这一段暂时将其叫做 $Z$ 。
得到 $Z$ 之后,它会被送到encoder的下一个模块,即Feed Forward Neural Network。这个全连接有两层,第一层的激活函数是ReLU,第二层是一个线性激活函数,可以表示为:
Encoder的结构如图4所示:
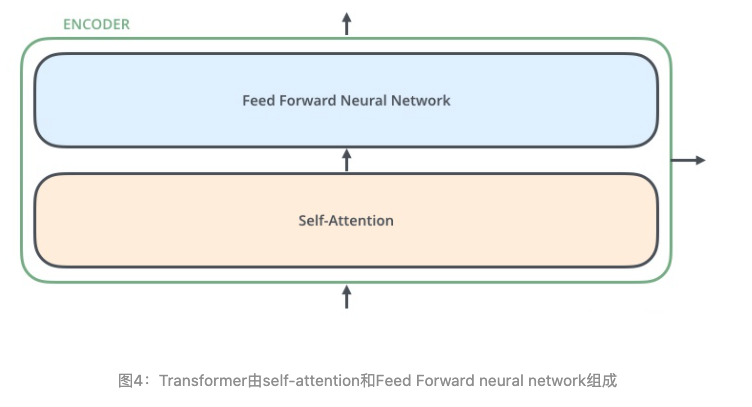
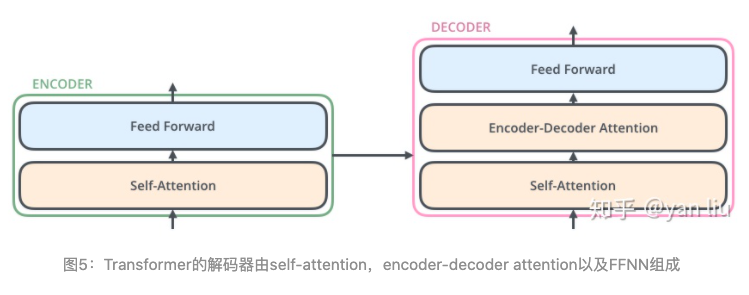
Decoder的结构如图5所示,它和encoder的不同之处在于Decoder多了一个Encoder-Decoder Attention,两个Attention分别用于计算输入和输出的权值:
- Self-Attention:当前翻译和已经翻译的前文之间的关系;
- Encoder-Decnoder Attention:当前翻译和编码的特征向量之间的关系。
输入编码
上节介绍的就是Transformer的主要框架,下面我们将介绍它的输入数据。如图6所示,首先通过Word2Vec等词嵌入方法将输入语料转化成特征向量,论文中使用的词嵌入的维度为 $d_{model}=512$ 。
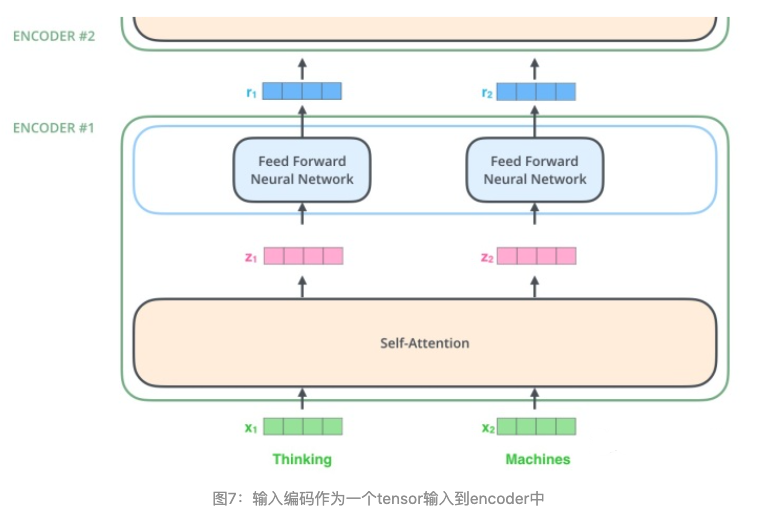
在最底层的block中, $x$ 将直接作为Transformer的输入,而在其他层中,输入则是上一个block的输出。为了画图更简单,我们使用更简单的例子来表示接下来的过程,如图7所示:
Self-Attention
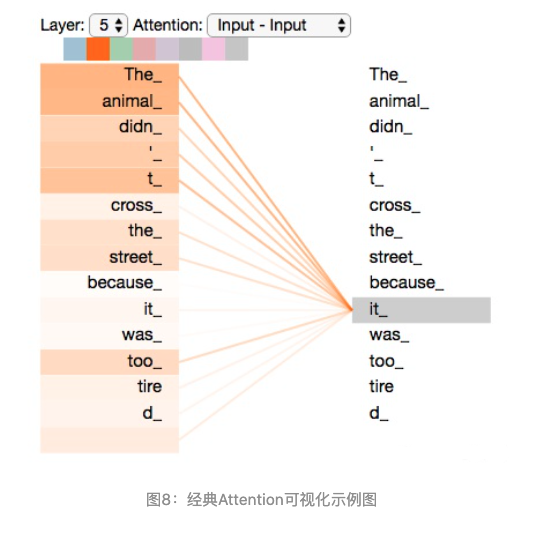
Self-Attention是Transformer最核心的内容,然而作者并没有详细讲解,下面我们来补充一下作者遗漏的地方。其核心内容是为输入向量的每个单词学习一个权重,例如在下面的例子中我们判断it代指的内容
The animal didn’t cross the street because it was too tired
通过加权之后可以得到类似图8的加权情况,在讲解self-attention的时候我们也会使用图8类似的表示方式
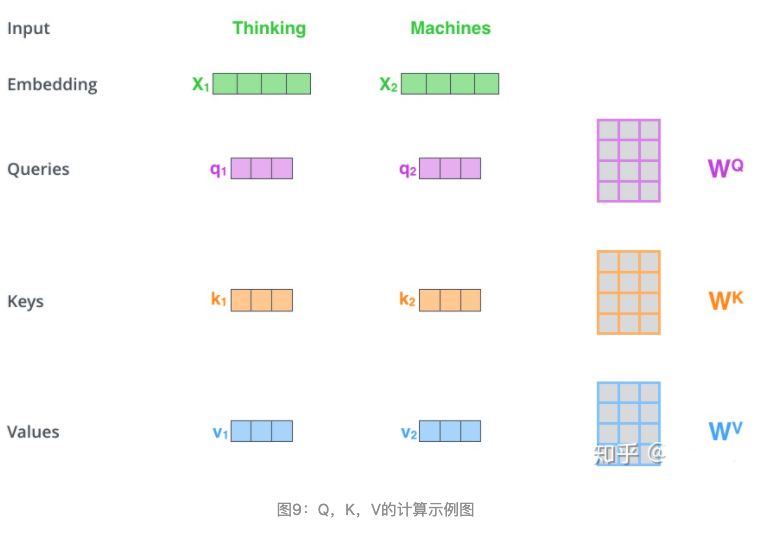
在self-attention中,每个单词有3个不同的向量,它们分别是Query向量( $Q$ ),Key向量( $K$ )和Value向量( $V$ ),长度均是64。它们是通过3个不同的权值矩阵由嵌入向量 $X$ 乘以三个不同的权值矩阵 $W^Q$ , $W^K$ , $W^V$ 得到,其中三个矩阵的尺寸也是相同的。均是 $512×64$ 。
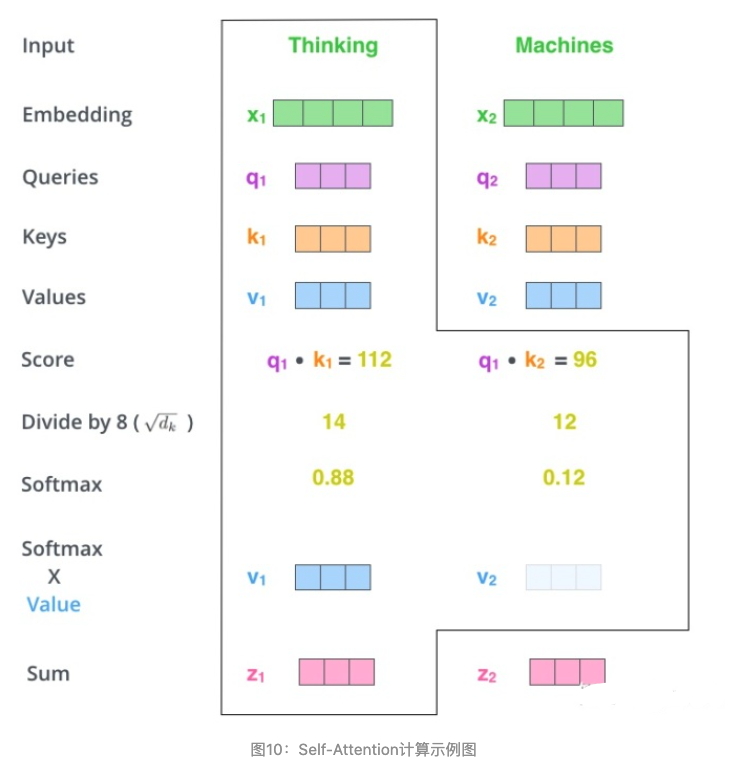
那么Query,Key,Value是什么意思呢?它们在Attention的计算中扮演着什么角色呢?我们先看一下Attention的计算方法,整个过程可以分成7步:
- 如上文,将输入单词转化成嵌入向量;
- 根据嵌入向量得到 $q$ , $k$ , $v$ 三个向量;
- 为每个向量计算一个score: $score=q・k$ ;
- 为了梯度的稳定,Transformer使用了score归一化,即除以 $\sqrt{d_k}$ ;
- 对score施以softmax激活函数;
- softmax点乘Value值 $v$ ,得到加权的每个输入向量的评分 $v$ ;
- 相加之后得到最终的输出结果 $z:z=\sum v$ 。
上面步骤的可以表示为图10的形式。
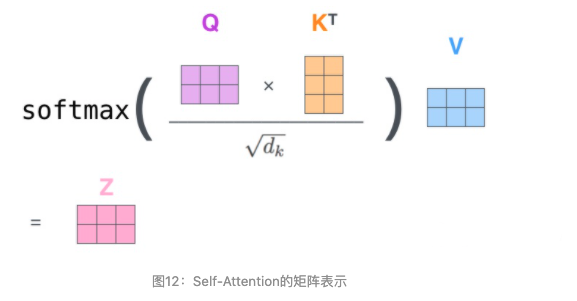
实际计算过程中是采用基于矩阵的计算方式,那么论文中的 $Q$ , $V$ , $K$ 的计算方式如图11:
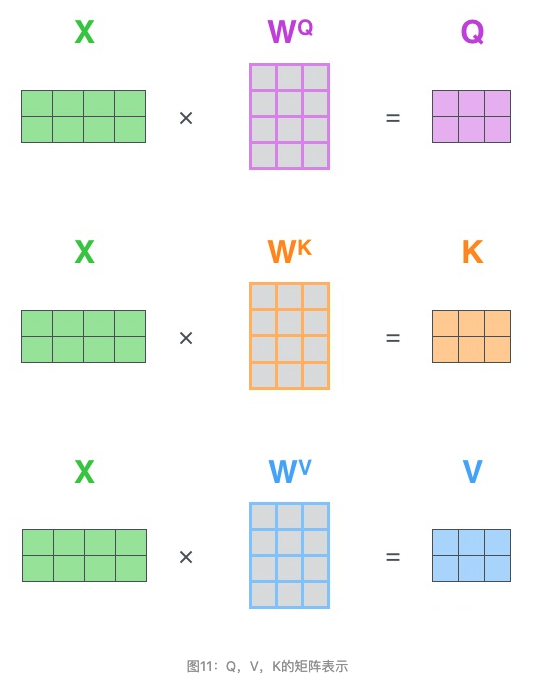
图10总结为如图12所示的矩阵形式:
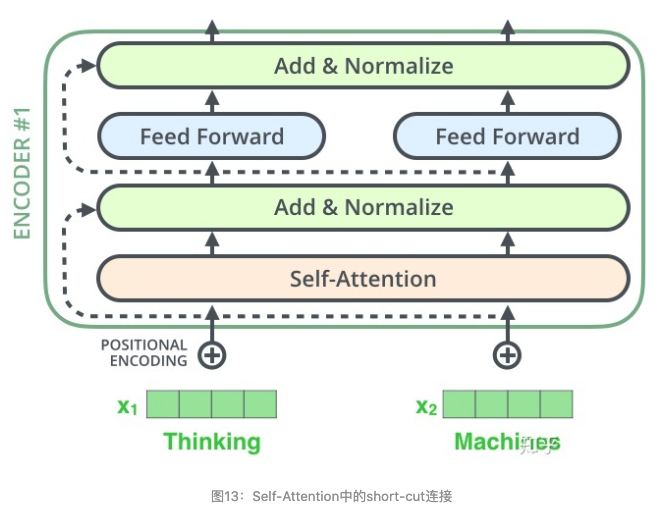
在self-attention需要强调的最后一点是其采用了残差网络中的short-cut结构,目的当然是解决深度学习中的退化问题,得到的最终结果如图13。
Query,Key,Value的概念取自于信息检索系统,举个简单的搜索的例子来说。当你在某电商平台搜索某件商品(年轻女士冬季穿的红色薄款羽绒服)时,你在搜索引擎上输入的内容便是Query,然后搜索引擎根据Query为你匹配Key(例如商品的种类,颜色,描述等),然后根据Query和Key的相似度得到匹配的内容(Value)。
self-attention中的Q,K,V也是起着类似的作用,在矩阵计算中,点积是计算两个矩阵相似度的方法之一,因此式1中使用了 $QK^T$ 进行相似度的计算。接着便是根据相似度进行输出的匹配,这里使用了加权匹配的方式,而权值就是query与key的相似度。
Multi-Head Attention
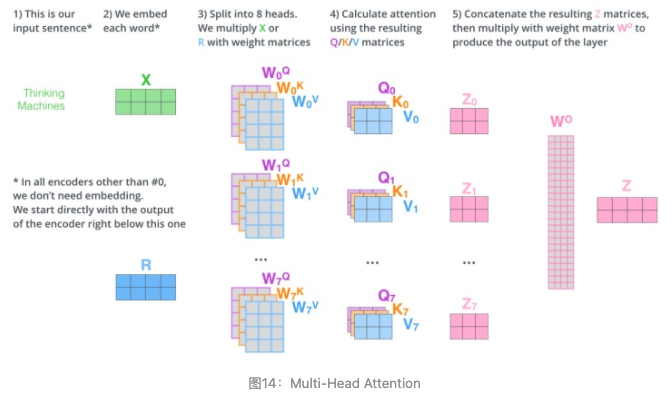
Multi-Head Attention相当于 $h$ 个不同的self-attention的集成(ensemble),在这里我们以 $h=8$ 举例说明。Multi-Head Attention的输出分成3步:
- 将数据 $X$ 分别输入到图13所示的8个self-attention中,得到8个加权后的特征矩阵 $Z_i,i\in\{1,2,…,8\}$ 。
- 将8个 $Z_i$ 按列拼成一个大的特征矩阵;
- 特征矩阵经过一层全连接后得到输出 $Z$ 。
整个过程如图14所示:
同self-attention一样,multi-head attention也加入了short-cut机制。
Encoder-Decoder Attention
在解码器中,Transformer block比编码器中多了个encoder-cecoder attention。在encoder-decoder attention中, $Q$ 来之与解码器的上一个输出, $K$ 和 $V$ 则来自于与编码器的输出。其计算方式完全和图10的过程相同。
由于在机器翻译中,解码过程是一个顺序操作的过程,也就是当解码第 $k$ 个特征向量时,我们只能看到第 $k-1$ 及其之前的解码结果,论文中把这种情况下的multi-head attention叫做masked multi-head attention。
损失层
解码器解码之后,解码的特征向量经过一层激活函数为softmax的全连接层之后得到反映每个单词概率的输出向量。此时我们便可以通过CTC等损失函数训练模型了。
而一个完整可训练的网络结构便是encoder和decoder的堆叠(各 $N$ 个, $N=6$ ),我们可以得到图15中的完整的Transformer的结构(即论文中的图1):
位置编码
截止目前为止,我们介绍的Transformer模型并没有捕捉顺序序列的能力,也就是说无论句子的结构怎么打乱,Transformer都会得到类似的结果。换句话说,Transformer只是一个功能更强大的词袋模型而已。
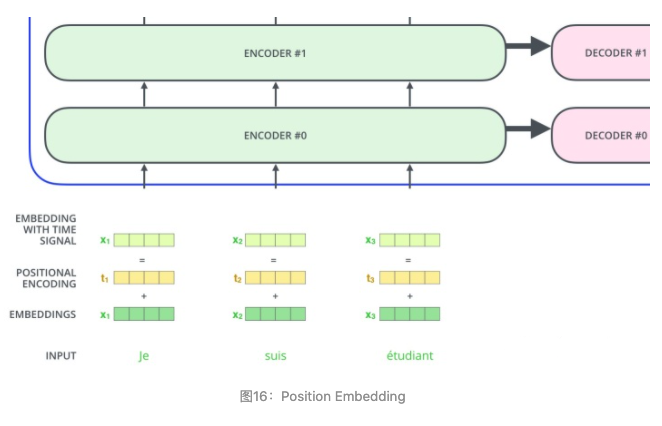
为了解决这个问题,论文中在编码词向量时引入了位置编码(Position Embedding)的特征。具体地说,位置编码会在词向量中加入了单词的位置信息,这样Transformer就能区分不同位置的单词了。
那么怎么编码这个位置信息呢?常见的模式有:a. 根据数据学习;b. 自己设计编码规则。在这里作者采用了第二种方式。那么这个位置编码该是什么样子呢?通常位置编码是一个长度为 $d_{model}$ 的特征向量,这样便于和词向量进行单位加的操作,如图16。
论文给出的编码公式如下:
在上式中, $pos$ 表示单词的位置, $i$ 表示单词的维度。关于位置编码的实现可在Google开源的算法中get_timing_signal_1d()函数找到对应的代码。
作者这么设计的原因是考虑到在NLP任务中,除了单词的绝对位置,单词的相对位置也非常重要。根据公式 $\sin(\alpha+\beta)=\sin\alpha \cos\beta + \cos\alpha \sin\beta$ 以及$\cos(\alpha+\beta)=\cos\alpha \cos\beta - \sin\alpha \sin\beta$ ,这表明位置 $k+p$ 的位置向量可以表示为位置 $k$ 的特征向量的线性变化,这为模型捕捉单词之间的相对位置关系提供了非常大的便利。
Layer normalization
在transformer中,每一个子层(self-attetion,ffnn)之后都会接一个残差模块,并且有一个Layer normalization
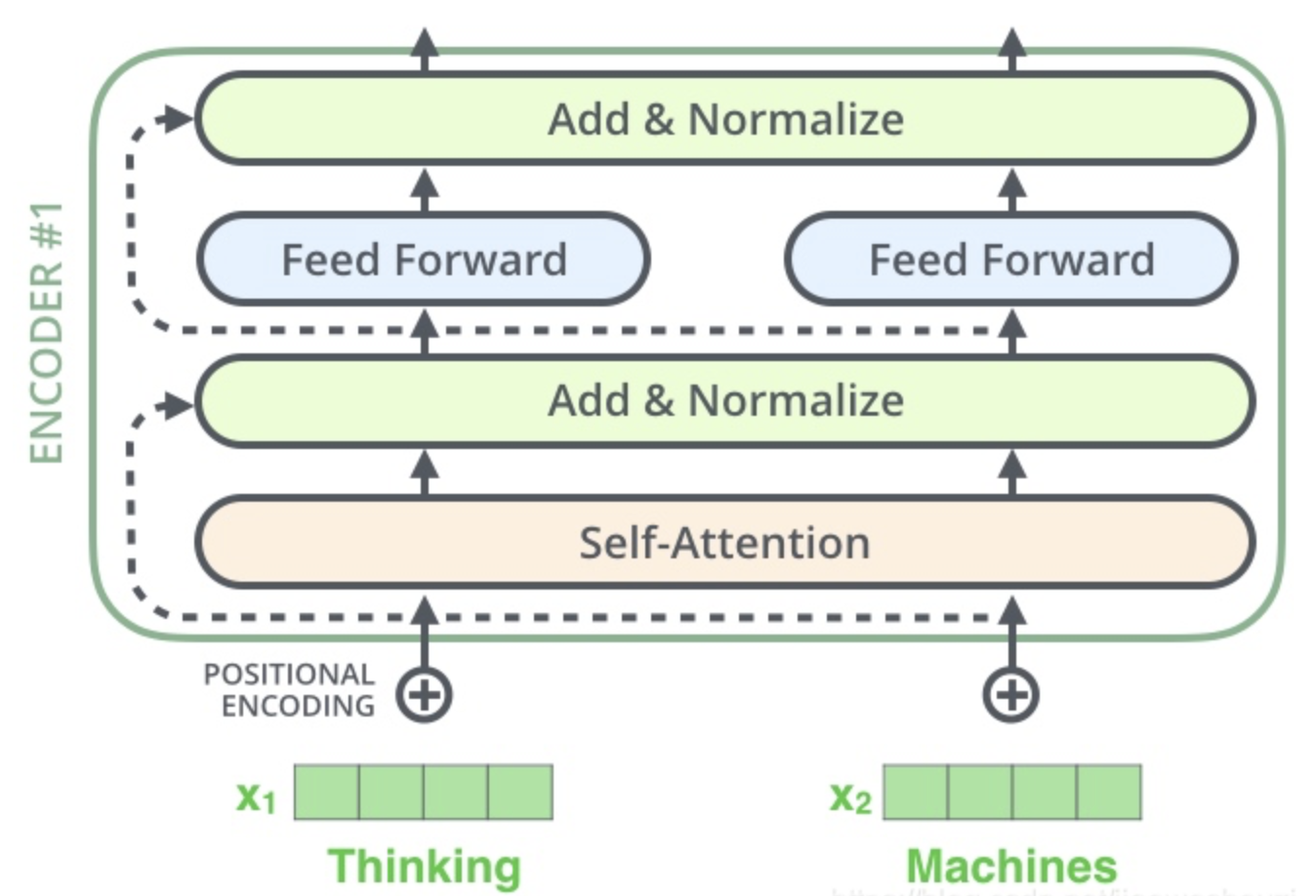
在进一步探索其内部计算方式,我们可以将上面图层可视化为下图:
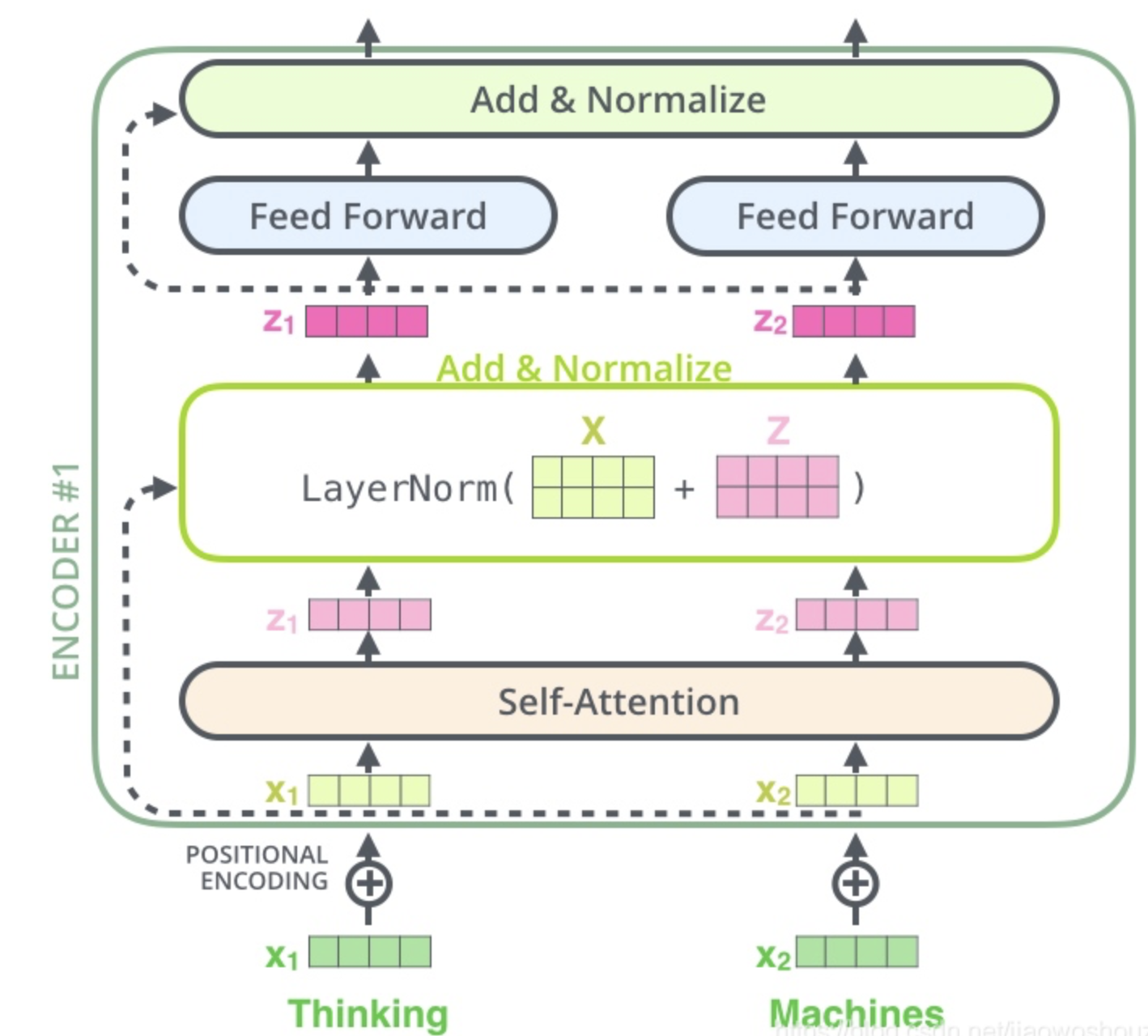
残差模块相信大家都很清楚了,这里不再讲解,主要讲解下Layer normalization。Normalization有很多种,但是它们都有一个共同的目的,那就是把输入转化成均值为0方差为1的数据。我们在把数据送入激活函数之前进行normalization(归一化),因为我们不希望输入数据落在激活函数的饱和区。
说到 normalization,那就肯定得提到 Batch Normalization。BN的主要思想就是:在每一层的每一批数据上进行归一化。我们可能会对输入数据进行归一化,但是经过该网络层的作用后,我们的数据已经不再是归一化的了。随着这种情况的发展,数据的偏差越来越大,我的反向传播需要考虑到这些大的偏差,这就迫使我们只能使用较小的学习率来防止梯度消失或者梯度爆炸。
BN的具体做法就是对每一小批数据,在批这个方向上做归一化。如下图所示: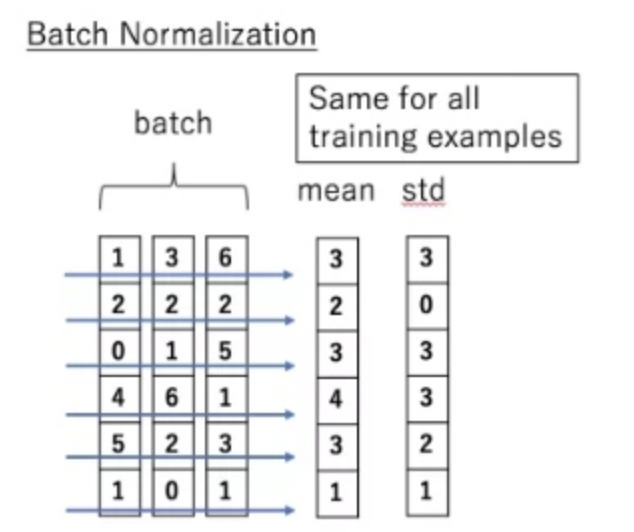
可以看到,右半边求均值是沿着数据 batch_size的方向进行的,其计算公式如下:
那么什么是 Layer normalization 呢?它也是归一化数据的一种方式,不过 LN 是在每一个样本上计算均值和方差,而不是BN那种在批方向计算均值和方差!
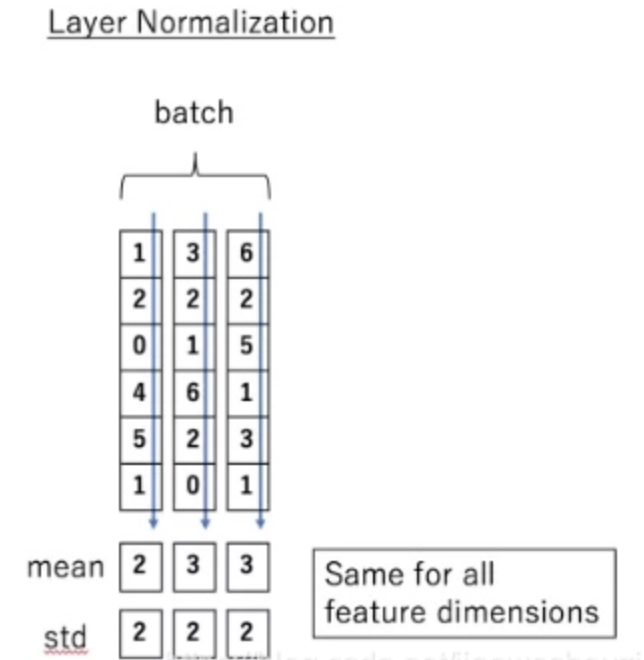
到这里为止就是全部encoders的内容了,如果把两个encoders叠加在一起就是这样的结构,在self-attention需要强调的最后一点是其采用了残差网络中的short-cut结构,目的是解决深度学习中的退化问题。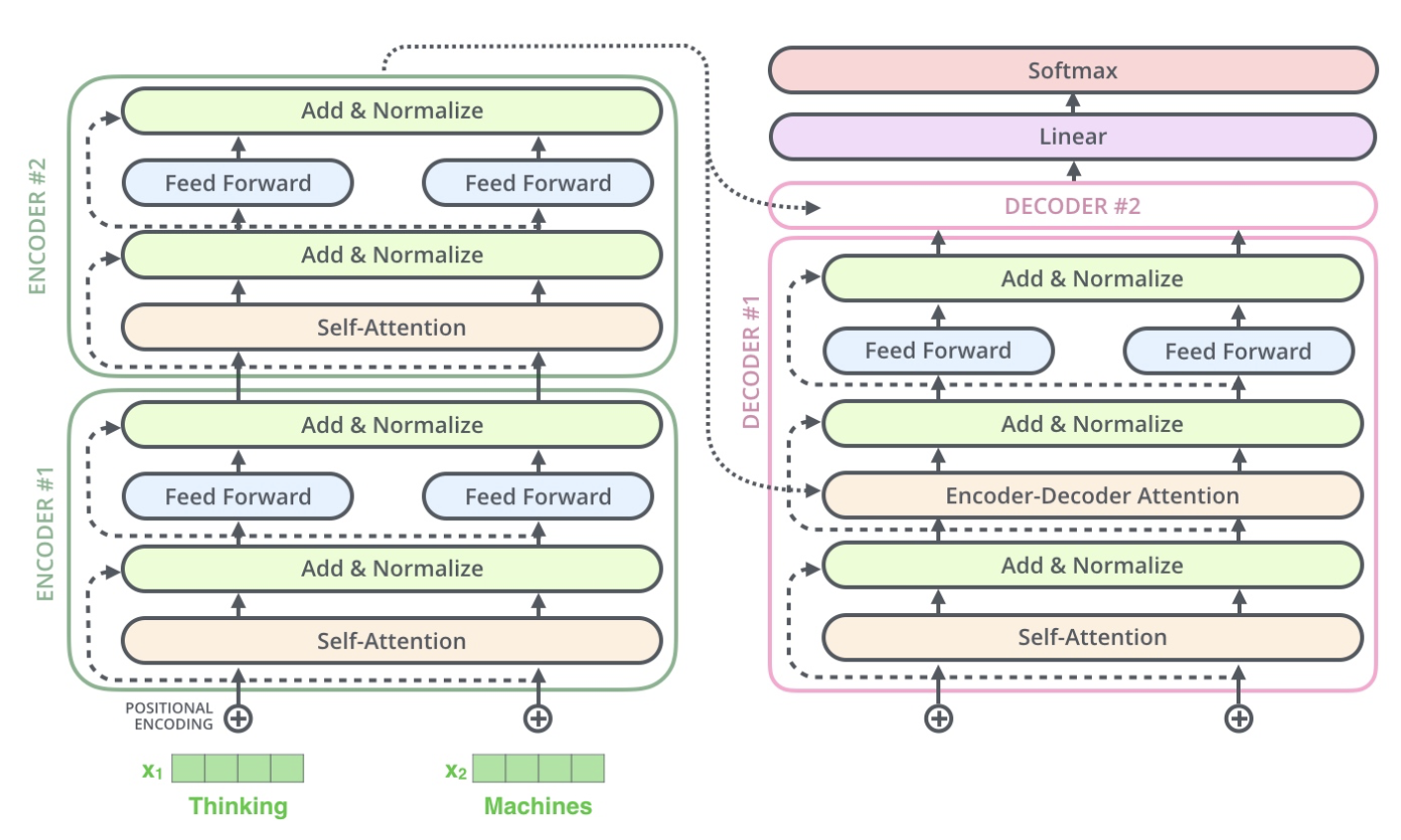
Decoder层
decoder部分其实和encoder部分大同小异,不过在最下面额外多了一个masked mutil-head attetion,这里的mask也是transformer一个很关键的技术,我们一起来看一下。
Mask
mask 表示掩码,它对某些值进行掩盖,使其在参数更新时不产生效果。Transformer 模型里面涉及两种 mask,分别是 padding mask 和 sequence mask。
其中,padding mask 在所有的 scaled dot-product attention 里面都需要用到,而 sequence mask 只有在 decoder 的 self-attention 里面用到。
Padding Mask
什么是 padding mask 呢?因为每个批次输入序列长度是不一样的也就是说,我们要对输入序列进行对齐。具体来说,就是给在较短的序列后面填充 0。但是如果输入的序列太长,则是截取左边的内容,把多余的直接舍弃。因为这些填充的位置,其实是没什么意义的,所以我们的attention机制不应该把注意力放在这些位置上,所以我们需要进行一些处理。
具体的做法是,把这些位置的值加上一个非常大的负数(负无穷),这样的话,经过 softmax,这些位置的概率就会接近0!
而我们的 padding mask 实际上是一个张量,每个值都是一个Boolean,值为 false 的地方就是我们要进行处理的地方。
Sequence mask
文章前面也提到,sequence mask 是为了使得 decoder 不能看见未来的信息。也就是对于一个序列,在 time_step 为 t 的时刻,我们的解码输出应该只能依赖于 t 时刻之前的输出,而不能依赖 t 之后的输出。因此我们需要想一个办法,把 t 之后的信息给隐藏起来。
那么具体怎么做呢?也很简单:产生一个上三角矩阵,上三角的值全为0。把这个矩阵作用在每一个序列上,就可以达到我们的目的。
对于 decoder 的 self-attention,里面使用到的 scaled dot-product attention,同时需要padding mask 和 sequence mask 作为 attn_mask,具体实现就是两个mask相加作为attn_mask。
其他情况,attn_mask 一律等于 padding mask。
编码器通过处理输入序列启动。然后将顶部编码器的输出转换为一组注意向量k和v。每个解码器将在其“encoder-decoder attention”层中使用这些注意向量,这有助于解码器将注意力集中在输入序列中的适当位置:
编码器通过处理输入序列启动。然后将顶部编码器的输出转换为一组注意向量k和v。每个解码器将在其“encoder-decoder attention”层中使用这些注意向量,这有助于解码器将注意力集中在输入序列中的适当位置:
总结
优点:
(1)虽然Transformer最终也没有逃脱传统学习的套路,Transformer也只是一个全连接(或者是一维卷积)加Attention的结合体。但是其设计已经足够有创新,因为其抛弃了在NLP中最根本的RNN或者CNN并且取得了非常不错的效果,算法的设计非常精彩,值得每个深度学习的相关人员仔细研究和品位。
(2)Transformer的设计最大的带来性能提升的关键是将任意两个单词的距离是1,这对解决NLP中棘手的长期依赖问题是非常有效的。
(3)Transformer不仅仅可以应用在NLP的机器翻译领域,甚至可以不局限于NLP领域,是非常有科研潜力的一个方向。
(4)算法的并行性非常好,符合目前的硬件(主要指GPU)环境。
缺点:
(1)粗暴的抛弃RNN和CNN虽然非常炫技,但是它也使模型丧失了捕捉局部特征的能力,RNN + CNN + Transformer的结合可能会带来更好的效果。
(2)Transformer失去的位置信息其实在NLP中非常重要,而论文中在特征向量中加入Position Embedding也只是一个权宜之计,并没有改变Transformer结构上的固有缺陷。