Multi-Task Label Embedding for Text Classification
论文来源:ACL 2018
论文链接:https://arxiv.org/abs/1710.07210
代码链接:https://github.com/guoyinwang/LEAM
概述
这篇文章将label embedding 应用到multi-task learning 当中,制造了一个统一的多任务学习框架。并且认为通过给赋予任务的label 语义信息,可以在多任务间进行迁移学习。
传统的多任务模型有三个缺陷:
缺少 label 信息:每个任务的标签都用独立的、没有意义的单热点向量来表示,例如情绪分析中的正、负,编码为 [1,0] 和 [0,1],可能会造成潜在标签信息的丢失。
鲁棒性不够好:网络结构被精心设计来建模多任务学习的各种关联,但大多数网络结构是固定的,只能处理两个任务之间的交互,即成对交互。当引入新的任务时,网络结构必须被修改,整个网络必须再次被训练。
不能迁移:对于人类来说,在学习了几个相关的任务之后,我们可以很容易的就可以处理一个全新的任务,这就是迁移学习的能力。以往大多数模型的网络结构都是固定的,不兼容的,以致于无法处理新的任务。
因此,作者提出了多任务 label embedding (MTLE),将每个任务的 label 也映射到语义向量中,类似于 word embedding 表示单词序列,从而将原始的文本分类任务转化为向量匹配任务。
利用label embedding 可以做到:
- 增加标签语义信息,帮助模型更好的分裂
- 可以灵活的增加任务,并且分为直接添加 hot-update 和重新训练 cold-update 方式
- 利用标签嵌入,将所有分类标签嵌入到同一个语义空间,这样就可以在任务间迁移
单任务学习和多任务学习
单任务学习
输入为文本序列:$x=\{x_1,x_2,…,x_T\}$
输出为类标签$y$或者one-hot表示$𝐲$
一个预训练好的lookup layer用于将每个单词$x_t$转换为其词嵌入向量$ⅹ_t∈R^d$,分类模型$f$用于对每个$ⅹ=\{ⅹ_1,ⅹ_2,…,ⅹ_T\}$产生一个预测$\hat{𝐲}$
训练目标是最小化其交叉熵损失函数
$N$表示训练样本的数量,$C$表示类的数量。
多任务学习
具有$K$个分类任务,$T_1,T_2,…,T_K$
模型$F$用于将$T_k$中的每一个$ⅹ^{(k)}$产生一个预测$\{\hat{y}^{(1)},\hat{y}^{(2)},…,\hat{y}^{(K)}\}$
这里只有$\hat{y}^{(k)}$会被用来计算损失。
$λ_k$表示权值,$N_k$表示样本数量,$C_k$表示任务$T_k$的类数量。
模型架构
作者提出了三种模型: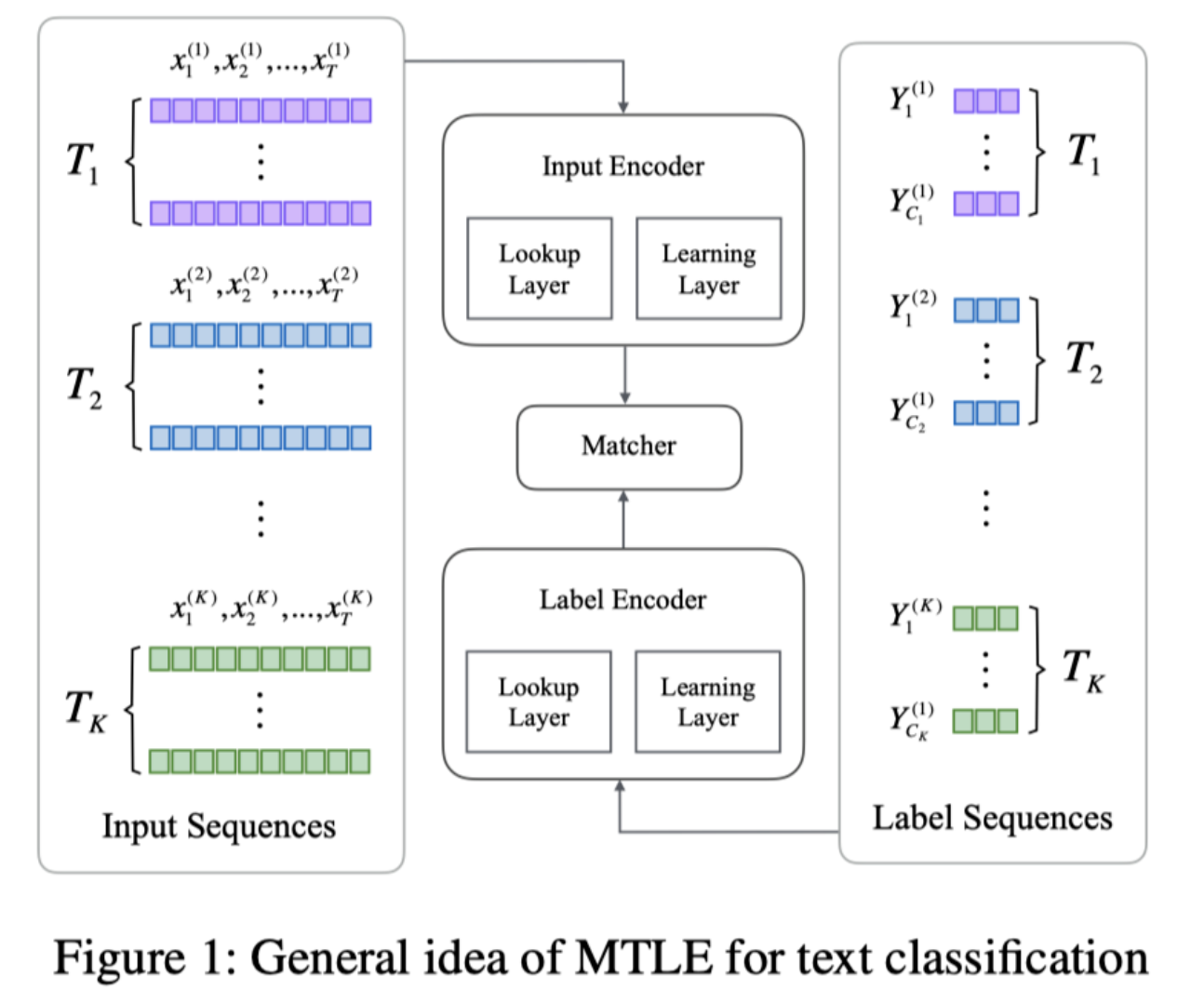
第一种假设对于每个任务,我们只有 N 个输入序列和 C 个分类标签,但是缺少每个输入序列和对应标签的具体标注。在这种情况下,只能以无监督的方式实现 MTLE。包含三个部分:input encoder, label encoder, matcher。两个 encoder 将文本编码成定长的向量。
第一种由于使用了非监督方法,performance 不如有监督的。
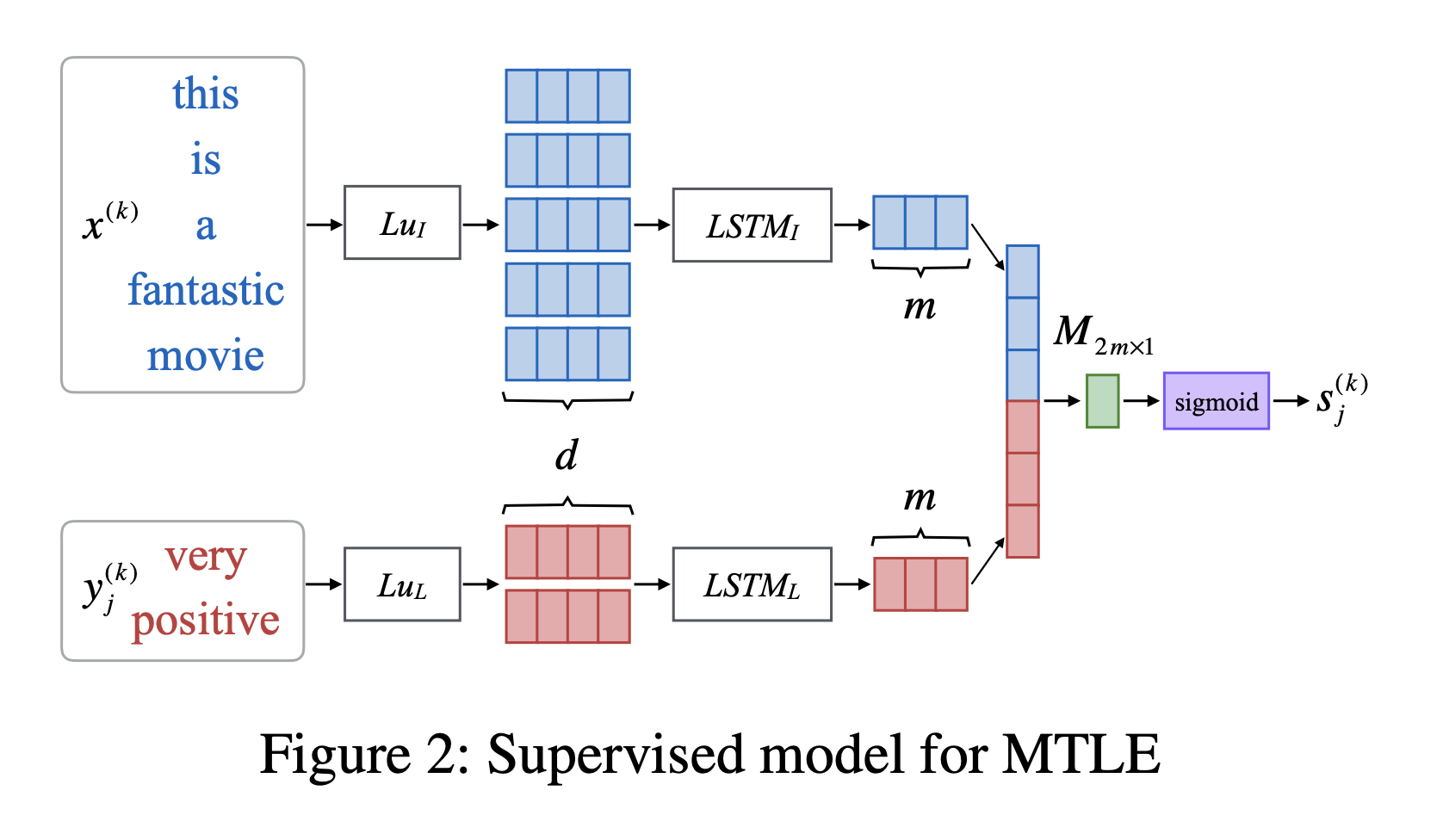
第二种就是有监督的了,两个 LSTM 分别对 label 和句子进行编码,之后分别 concat,过一层全连接(),得到 logits,个人感觉这个交互做的过于简单。
$⊕$表示矩阵拼接。
第三种则是基于 MTLE 的半监督学习模型。
第二种和第三种之间唯一的不同是它们处理新任务的方式。如果新任务有标签,可以选择第二种的 Hot-Update 或 Cold-Update。如果新的任务完全没有标记,仍然可以使用第二种进行向量映射,无需进一步训练就可以为每个输入序列找到最佳的标记(但是还是映射到原来就有的 label 里),作者将其定义为 Zero-Update。
Hot-Update、Cold-Update 和 Zero-Update 之间的区别如下图所示,其中, Before Update 表示在引入新任务之前对旧任务进行训练的模型。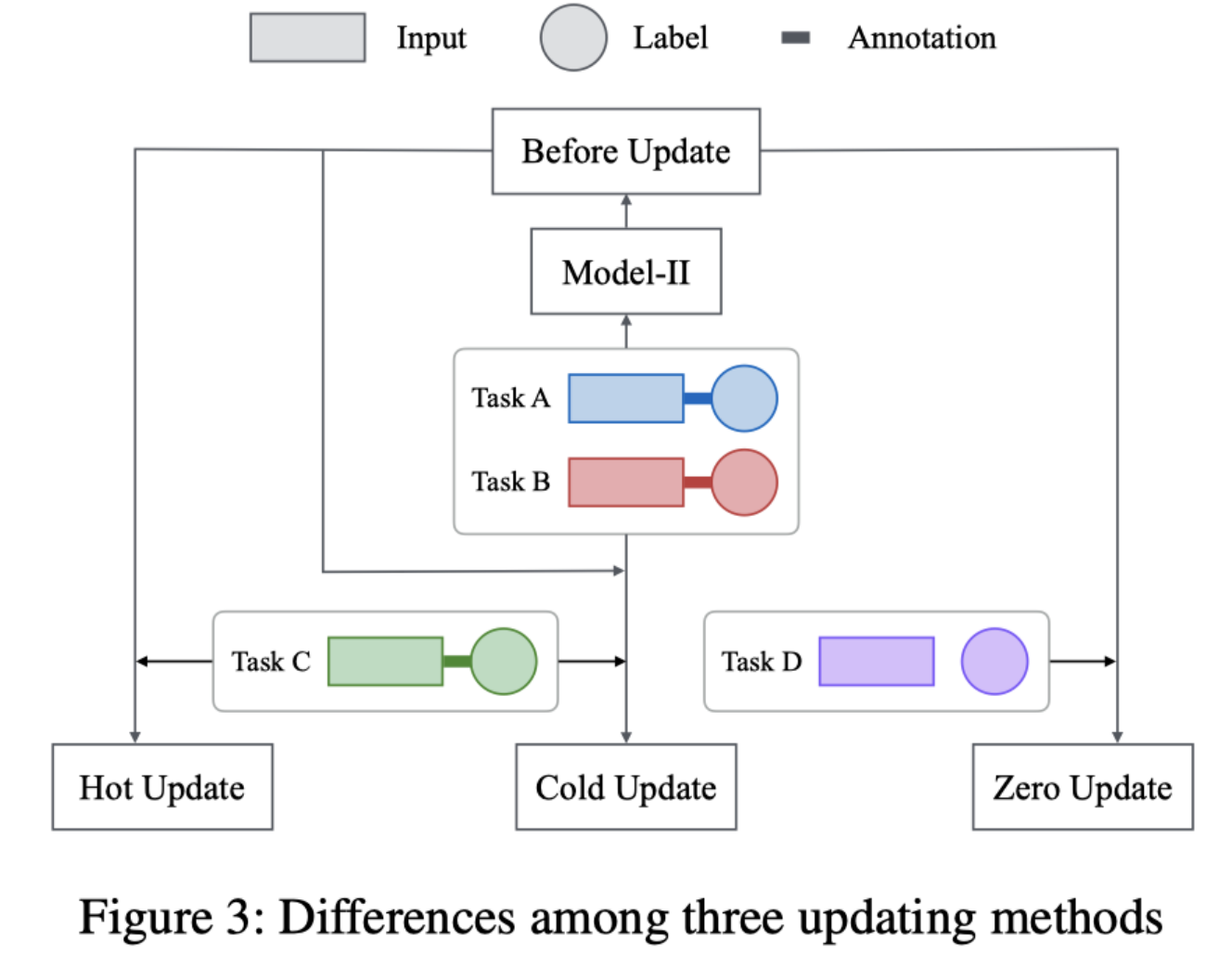
Hot-Update: 在训练过多个 task 的模型基础上进行 finetune。
Cold-Update: 在所有的 tasks 上重新训练。
Zero update: 不更新模型。利用训练过的模型在新 task 上直接得出结果。